这是leveldb源代码包中提供的 readme.md,index.md 的部分翻译文档,不是逐字逐句翻译,只是把自己感兴趣的部分翻译出来了,作为看代码之前的准备工作。
1.公共接口
include文件夹下面的是公共接口,所有使用者应该从这里的头文件直接调用。
- include/db.h:数据库的主接口:从这里开始
- include/options.h:控制整个数据的行为,也控制数据库的读写,可以看做是配置文件。
- include/comparator.h:用户自定义的比较函数的抽象。如果想要使用基于字节的方法对键大小进行比较,可以使用默认的比较器,用户也可以自己实现比较器来按自己的想法对存储进行排序。
- include/iterator.h:遍历数据的接口。可以从DB对象中获取这样一个迭代器。
- include/write_batch.h:对数据库原子的进行多个更新操作的接口。
- include/slice.h:一个简单的模块,用来维护一个指针和长度,来表示一个字节数组。
- include/status.h:用来汇报成功或是其他各种各样的错误。
- include/env.h:操作系统环境的抽象。这个接口的posix实现是在util/env_posix.cc中
- include/table.h,include/table_builder.h:低层次的模块,绝大多数客户端不会使用这个接口。
2.leveldb基本使用
leveldb提供持久化的键值存储。键和值是任意的字节数组。键值对的存储是按照键的顺序存储的,并且这个顺序是按照用户自定义的排序函数来的。
2.1 打开一个数组库
leveldb存储是使用文件系统中的文件夹。所有数据库内容都会存储在这个文件夹里。下面是一个打开数据库的例子,并且如果数据库不存在会自动创建:
#include <cassert>
#include "leveldb/db.h"
leveldb::DB* db;
leveldb::Options options;
options.create_if_missing = true;
leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db);
assert(status.ok());
如果希望在数据库已经存在时报错,在leveldb::DB::Open前调用:
options.error_if_exists = true;
2.2 状态
上面的代码中使用了leveldb::Status类型,leveldb中大多数函数都会返回这个值。你可以检查这个值是不是ok,或者打印出相关的错误。
leveldb::Status s = ....;
if (!s.ok()) cerr << s.ToString() << endl;
2.3 关闭数据库
如果数据库操作结束后,删除数据库对象即可关闭
.... open the db as described above ...
.... do something with db ....
delete db;
2.4 读写
数据库提供了Put、Delete、Get方法来修改/查询数据库。例如,下面的代码用来将key1的值移动到key2中。
std::string value;
leveldb::Status s = db->Get(leveldb::ReadOptions(), key1, &value);
if (s.ok()) s = db->Put(leveldb::WriteOptions(), key2, value);
if (s.ok()) s = db->Delete(leveldb::WriteOptions(), key1);
2.5 原子更新
上面的例子中,如果在Put完key2的值,Delete key1的值前,进程崩溃了,同一个值就会被存储在多个key下。使用WriteBatch类可以原子的执行多个更新操作:
#include "leveldb/write_batch.h"
....
std::string value;
leveldb::Status s = db->Get(leveldb::ReadOptions(), key1, &value);
if (s.ok()) {
leveldb::WriteBatch batch;
batch.Delete(key1);
batch.Put(key2, value);
s = db->Write(leveldb::WriteOptions(), &batch);
}
WriteBatch存储了一系列的对数据库的编辑操作,这些操作会被顺序执行。注意到我们先执行了Delete,再执行Put,这样当key1和key2相同时,我们不会错误的删除所有的值。
WirteBatch不仅仅有原子操作的特点,还可以用来加速大量的更新操作。原理是将大量的单独的变化放入同一个批操作中。
2.6 同步写入
默认情况下,对leveldb的写入都是异步的:它在将进程中的写操作提交给操作系统后返回。数据从操作系统内存转移到持久化存储这个过程是异步的(也就是和这里不会等持久化之后才返回)。使用同步写入,可以让某些特定的写入等到数据被写入持久化存储后才返回。(在Posix系统中,这个通过调用 fsync(....) 或 fdatasync(....) 或 msync(...., MS_SYNC) 来实现。
leveldb::WriteOptions write_options;
write_options.sync = true;
db->Put(write_options, ....);
异步写入通常情况下是千百倍的快于同步写入。异步写入的缺点是如果机器崩溃可能会造成最后的一些更新丢失。注意仅仅是写进程的崩溃不会造成任何数据丢失,即使没有使用同步写。因为写进程只负责将写操作提交给操作系统,提交完就意味着写入已经结束(即使这个时候没有真正的写入到持久化存储中)。
异步写大多数时候都能被安全使用。比如,当载入大量数据到数据库中,如果出现崩溃你可以重新开始这个载入操作。也可以使用混合写入模式,也就是每多少个异步写之后使用一次同步写。如果崩溃了,可以从上一次同步写开始(同步写会产生一个标记,所以可以从上一次同步写开始)。
WriteBatch对于异步写提供了多个选择。多个更新操作也被放在同一个批操作中,然后使用一个同步写被一起执行(write_options.sync设置为true)。同步写产生的额外性能消耗被均摊在所有的写操作上。
2.7 并发
数据库在同一时间只能由一个进程打开。leveldb使用了操作系统的锁来防止被错误使用。在一个单进程中,同一个leveldb::DB对象可以被多个并发线程安全的共享。不同的线程之间在对同一个数据库对象写入或者遍历或者调用Get时,不需要额外的同步操作(leveldb的实现会自动做这个必要的同步操作。然而其他对象(比如Iterator和WriteBatch)可能需要额外的同步。如果两个线程共享了这样的对象,它们必须使用它们自己的锁协议来保护对象的使用。更多的细节可以在公共头文件中看到。
2.8 迭代器(Iteration)
下面的例子展示了如何打印一个数据库中所有的键值对。
leveldb::Iterator* it = db->NewIterator(leveldb::ReadOptions());
for (it->SeekToFirst(); it->Valid(); it->Next()) {
cout << it->key().ToString() << ": " << it->value().ToString() << endl;
}
assert(it->status().ok()); // Check for any errors found during the scan
delete it;
下面的例子展示了如何显示一个特定范围的数据
[start,limit):
for (it->Seek(start);
it->Valid() && it->key().ToString() < limit;
it->Next()) {
....
}
你也可以倒序遍历所有的数据(倒序比正序可能要慢)
for (it->SeekToLast(); it->Valid(); it->Prev()) {
....
}
2.9 快照(Snapshots)
快照提供了键值存储所有状态一致的只读视图。ReadOptions::snapshot可能是non-NULL的值,来表示一个读操作应该执行在特定的DB状态版本上。如果 ReadOptions::snapshot是NULL,读操作可能执行在当前状态的隐式快照上。
快照的创建:DB::GetSnapshot()
leveldb::ReadOptions options;
options.snapshot = db->GetSnapshot();
.... apply some updates to db ....
leveldb::Iterator* iter = db->NewIterator(options);
.... read using iter to view the state when the snapshot was created ....
delete iter;
db->ReleaseSnapshot(options.snapshot);
当一个快照不需要的时候,使用DB::ReleaseSnapshot接口来释放。
2.10 片(Slice)
*Slice不知道翻译成什么*
it->key()和it->value()的返回值都调用了leveldb::Slice类型的实例。Slice是一个简单的结构:包含字节数组的长度和指针。返回一个Slice比返回std::string是一个更轻量划算的选择,因为我们不需要复制潜在的很大的键和值(返回的是指针和长度)。额外的,leveldb的方法不返回null-terminated(\0结尾)的 C-style 字符串,因为leveldb的键和值是允许存储'\0'字节的。
Slice和C++字符串以及C-style字符串之间可以互相转换。
leveldb::Slice s1 = "hello";
std::string str("world");
leveldb::Slice s2 = str;
std::string str = s1.ToString();
assert(str == std::string("hello"));
使用Slice时要小心,因为Slice取决于调用者来保证Slice中存储的数据的生命周期。下面就是一段有问题的代码的示例:
leveldb::Slice slice;
if (....) {
std::string str = ....;
slice = str;
}
Use(slice);
当执行到if外面的时候,str被销毁,slice中的存储也就消失了(注:这是因为slice中存储的是指针和长度)。
2.11 比较器(Comparators)
前面的例子使用的都是默认的排序函数来对键做排序,是对字节做字典排序的。当打开数据库的时候,可以使用自定义的比较器来排序。例如,假设每个数据的键都由两个数字组成,我们应该使用第一个数字来排序,使用第二个数字来打破联系。首先,定义一个合适的leveldb::Comparator的子类。
class TwoPartComparator : public leveldb::Comparator {
public:
// Three-way comparison function:
// if a < b: negative result
// if a > b: positive result
// else: zero result
int Compare(const leveldb::Slice& a, const leveldb::Slice& b) const {
int a1, a2, b1, b2;
ParseKey(a, &a1, &a2);
ParseKey(b, &b1, &b2);
if (a1 < b1) return -1;
if (a1 > b1) return +1;
if (a2 < b2) return -1;
if (a2 > b2) return +1;
return 0;
}
// Ignore the following methods for now:
const char* Name() const { return "TwoPartComparator"; }
void FindShortestSeparator(std::string*, const leveldb::Slice&) const {}
void FindShortSuccessor(std::string*) const {}
};
现在使用这个比较器来打开数据库:
TwoPartComparator cmp;
leveldb::DB* db;
leveldb::Options options;
options.create_if_missing = true;
options.comparator = &cmp;
leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db);
....
2.11.1 向后兼容
比较器的Name()方法的返回值在数据库被创建时就已经联系起来了,在之后的每次数据库打开时都会被检查。如果name改变了,leveldb::DB::Open调用时会失败。因此,当且仅当新的键格式和比较函数和已经存在的数据库不兼容时,才会改变name的值,这时不得不丢弃所有已经存在的数据。
当然你也可以通过一些提前的计划来逐步的拓展你的键格式。例如,你可以存储一个版本号在每一个键的末尾(一个字节就够用了)。当你想要改变到新的键格式(例如添加第三个部分到键上)
– (a) 保持同样的比较器名字
– (b) 增加新的键的版本号
– (c) 改变比较函数,使用键的版本号来决定如何解释这些键
2.12 性能
性能可以通过改变配置文件来调节
include/leveldb/options.h
2.13 块大小
leveldb将相邻的键合成一组存储在同一个块中,这样的块是从持久化存储和内存间转移的最小单元。默认的块大小是大约4096个未压缩的字节。如果应用程序总是在数据库中做大量的扫描,可以考虑适当增加这个值的大小。应用程序做大量的很小的值的点读取,可以考虑使用小一点的块大小(如果这些设置确实提升了性能)。如果块大小小于1kilobyte,或者大于几个megabytes是没有太多好处的。注意对于更大的块大小使用压缩会更有效率。
2.14 压缩
每一个数据块在写入持久化存储前会单独的被压缩,压缩是默认的,因为默认的压缩函数是非常快的。对于不可压缩的数据会自动禁用。在极少数的例子中,程序可能会希望完全禁用压缩,仅仅当性能测试显示性能提升了才推荐这么做。
leveldb::Options options;
options.compression = leveldb::kNoCompression;
.... leveldb::DB::Open(options, name, ....) .....
2.15 缓存
数据库的内容被存储在文件系统的文件集合中。每一个文件存储了一系列的压缩的数据块。如果options.cache是non-NULL的,经常使用的未压缩的数据块内容将会被缓存。
#include "leveldb/cache.h"
leveldb::Options options;
options.cache = leveldb::NewLRUCache(100 * 1048576); // 100MB cache
leveldb::DB* db;
leveldb::DB::Open(options, name, &db);
.... use the db ....
delete db
delete options.cache;
注意缓存保存了未压缩的数据,因此根据程序级的数据量来设置缓存的大小,使用压缩的数据不会有任何的减少。(压缩的数据块的存储留给操作系统缓冲区缓存,或者客户端的其他自定义环境变量来实现)
当执行大量的读取操作时,应用程序最好禁用缓存,这样大量的数据读取不会导致缓存内容大量被改变。per-iterator选项用来实现这个:
leveldb::ReadOptions options;
options.fill_cache = false;
leveldb::Iterator* it = db->NewIterator(options);
for (it->SeekToFirst(); it->Valid(); it->Next()) {
....
}
2.15.1 键层(Key Layout)
注意硬盘中转移和缓存的单元是一个数据块。相邻的键(根据数据库排序顺序)将被放在同一个数据块中。因此应用程序通过将所有的键依次相邻的排放,将不常访问的值内容(通过key来索引)放在另外一个区域可以提升程序性能。
举例来说,假设我们正在在leveldb上实现一个简单的文件系统,下面的入口类型我们可能希望存储。
filename -> permission-bits, length, list of file_block_ids
file_block_id -> data
我们可能想要设置filename的键前缀为一个字母(‘/’),file_block_id的键前缀为另一个字母(‘0’),因此扫描这些元数据不会强制我们取出和缓存大量的文件内容。
2.16 过滤器
因为leveldb的数据在磁盘上有结构地存放,一个简单的Get()可能调用多个从磁盘的读取。选项 FilterPolicy机制可以被用来减少磁盘读取的次数。
leveldb::Options options;
options.filter_policy = NewBloomFilterPolicy(10);
leveldb::DB* db;
leveldb::DB::Open(options, "/tmp/testdb", &db);
.... use the database ....
delete db;
delete options.filter_policy;
上面的代码将一个基于过滤策略的布隆过滤器(Bloom filter)和数据库联系起来。布隆过滤器的基础过滤依赖于保存每个键的一些位的数据在内存中(在这个例子中每个键有10个bit)。这个过滤器将会减少Get()带来的不必要的磁盘读取的次数大概为100。增加保存的每个键的bit数会更明显的减少读取次数,但是这是在更多的内存消耗的代价上得来的(注:典型的以空间换时间)。我们建议应用程序工作时还剩很多的内存,并且会做大量的随机读取时,设置一个过滤策略。
(注:布隆过滤器是一个针对于大数据量的去重算法,它会通过多个hash将一个字节数组映射到一个很大的bit向量中的k个位置,通过检查一个字节数组hash后的k个位置对应的bit向量是否都为1,如果不是则这个字节数组没有出现过,否则出现过(会有少量的误报)。使用在这里,是为了在读取前检查这个键是否存在,如果不存在则避免了以此全数据库查询,从而大大的提升的性能)
如果你使用一个自定义的比较器,你应该保证你正在使用的过滤策略是和你比较器兼容的。例如,想象一个比较器比较键时忽略了末尾的空间,NewBloomFilterPolicy不能和这样的比较器一起使用。相反的,应用程序需要提供一个自定义的过滤策略同样忽略这些末尾的空间。比如:
class CustomFilterPolicy : public leveldb::FilterPolicy {
private:
FilterPolicy* builtin_policy_;
public:
CustomFilterPolicy() : builtin_policy_(NewBloomFilterPolicy(10)) {}
~CustomFilterPolicy() { delete builtin_policy_; }
const char* Name() const { return "IgnoreTrailingSpacesFilter"; }
void CreateFilter(const Slice* keys, int n, std::string* dst) const {
// Use builtin bloom filter code after removing trailing spaces
std::vector<Slice> trimmed(n);
for (int i = 0; i < n; i++) {
trimmed[i] = RemoveTrailingSpaces(keys[i]);
}
return builtin_policy_->CreateFilter(&trimmed[i], n, dst);
}
};
有一些应用程序可能提供其他过滤策略不使用布隆过滤器,而是使用其他的机制来处理键的集合。细节看leveldb/filter_policy.h
2.17 校验(Checksums)
leveldb会校验所有存储在文件系统中的数据。这里有两个不相关的控制部分提供积极的校验:
ReadOptions::verify_checksums可被设置为true,强制校验从文件系统一次读取的所有数据。默认情况是不会做这个验证的。
Options::paranoid_checks在打开数据库之前可被设置为true,来使得数据库一旦检查到内部错误立马报错。这取决于数据库的哪一部分出错,当数据库被打开时还是其他后来的操作时,这个错误会被警告。默认情况下,偏执检查是关闭的,因此即使有时候持久化存储已经出错了,数据库依然可以被使用。
如果一个数据库出错了(可能它在偏执检查开启时不能打开), leveldb::RepairDB方法会尽可能的修复数据库的数据。
2.18 近似大小
GetApproximateSizes方法可以用来通过一个或多个键范围来获取文件系统已用的空间的近似字节数
leveldb::Range ranges[2];
ranges[0] = leveldb::Range("a", "c");
ranges[1] = leveldb::Range("x", "z");
uint64_t sizes[2];
leveldb::Status s = db->GetApproximateSizes(ranges, 2, sizes);
前面的代码调用将会设置sizes[0]为键范围在[a..c)之间的数据使用的文件系统存储空间的大小,设置sizes[1]为键范围在[x..z)之间的数据使用的文件系统存储空间的大小。
2.19 环境
所有的文件操作(以及其他的系统调用)都在leveldb:Env中实现了。复杂的客户端可能希望提供它们自己的Env的实现来获得更好的控制。例如,一个应用程序可能会在文件IO中引入人为延迟,限制leveldb对系统其他活动的影响。
class SlowEnv : public leveldb::Env {
.... implementation of the Env interface ....
};
SlowEnv env;
leveldb::Options options;
options.env = &env;
Status s = leveldb::DB::Open(options, ....);
2.20 移植(Porting)
leveldb可能通过提供被leveldb/port/port.h导出的类型/方法/函数/的平台相关的实现,来移植到新的平台。详细内容参考leveldb/port/port_example.h
另外的,新的平台可能需要新的默认leveldb::Env的实现。详细内容参考leveldb/util/env_posix.h
2.21 其他信息
其他信息可以参考其他的文档文件
1. impl.md
2. table_format.md
3. log_format.md
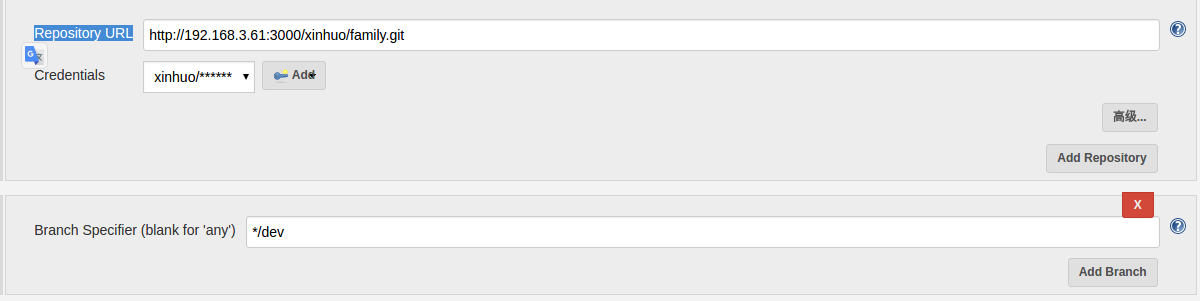 仓库地址可以是HTTP协议,也可以是SSH协议,然后记得在Credentials字段填入认证信息,HTTP协议可以是用户名和密码,SSH的话可以是秘钥。选择的是dev分支。之后在填写构建信息。
仓库地址可以是HTTP协议,也可以是SSH协议,然后记得在Credentials字段填入认证信息,HTTP协议可以是用户名和密码,SSH的话可以是秘钥。选择的是dev分支。之后在填写构建信息。 构建命令主要就是执行一个脚本
构建命令主要就是执行一个脚本