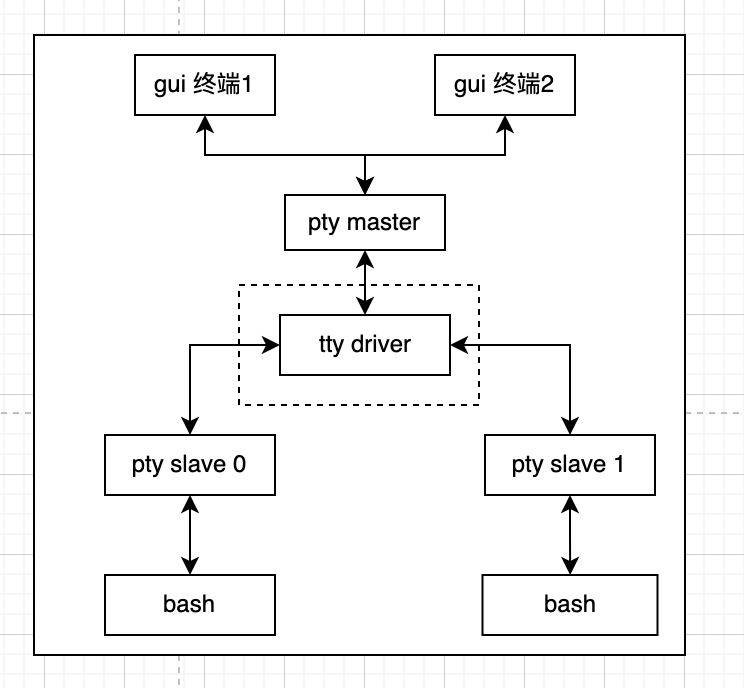
OpenFlow 里有一个重要的概念—流表(FlowTable),通过 Flow Table,我们可以制定交换机处理流量的行为。因此,理解流表匹配规则,是理解 OpenFlow 的重要一环。
OpenvSwitch(下文称为OVS) 是一个开源的软件交换机的实现,同时也是支持 OpenFlow 的,因此下文也会通过 OVS 来说明流表是如何匹配的。
流表匹配规则
流表项
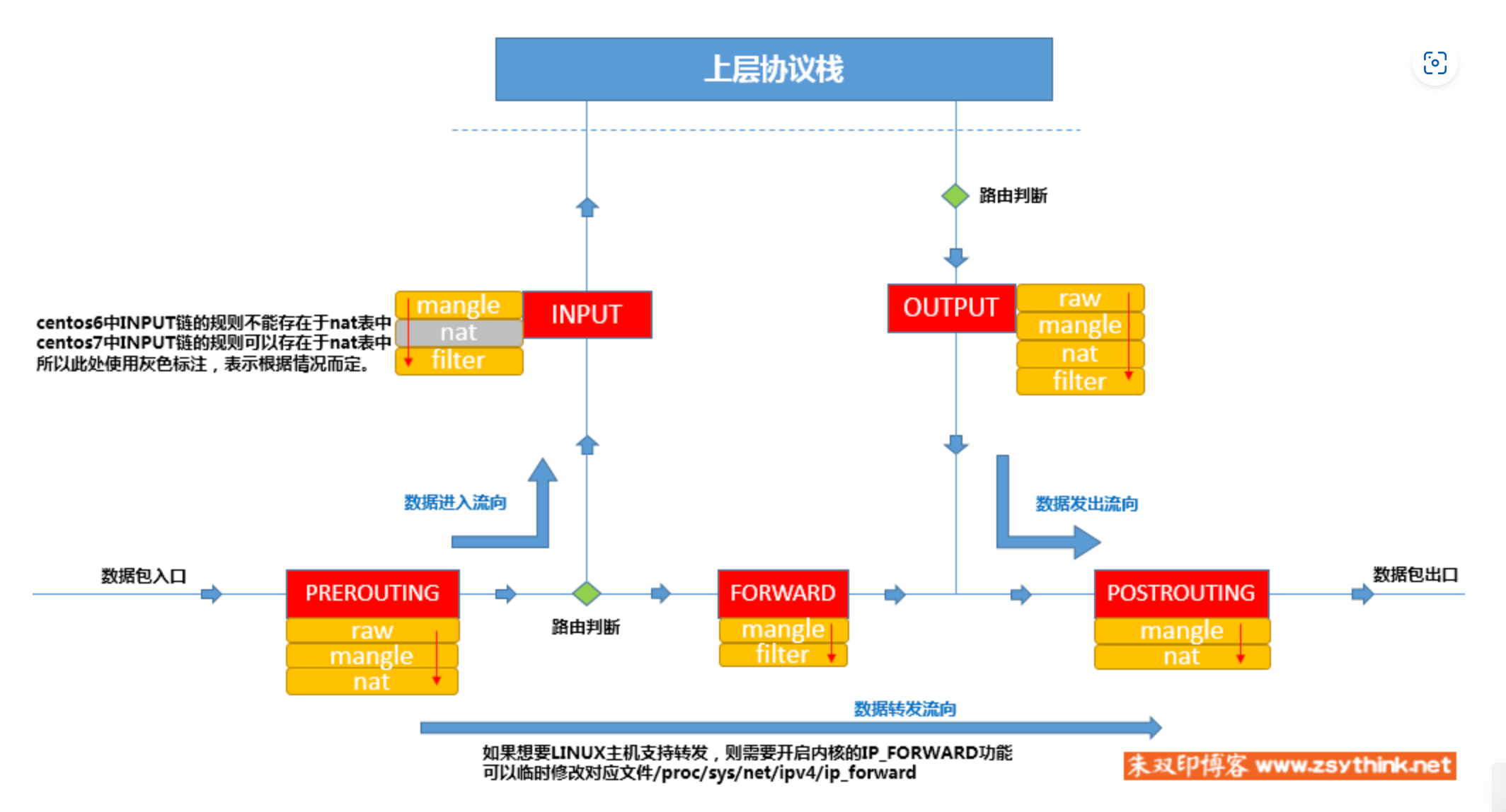
在一个 OpenFlow 的网络中,每一个支持 OpenFlow 的交换机都必须包含至少 1 个流表(table 0),这个流表里会包含 0 或多个流表项。这些流表项描述了流量的匹配规则,计数器以及如果针对这些流量做出动作。
一个流表项通常由以下元素组成
| 字段 |
描述 |
| Match Fileds |
用来匹配数据包 |
| Priority |
匹配流表项的优先级。如果一个数据包被多个流表项匹配到,则会根据优先级进行选择 |
| Counters |
当数据包被匹配成功时会更新该字段,主要用来流量统计 |
| Instructions |
用来修改 Actions 或 流水线处理 |
| Timeouts |
流表项的超时时间 |
| Cookie |
一些不透明的数据值。控制器可以使用它来过滤流量统计,流量修改和流量删除。在处理数据包时不使用这些数据值 |
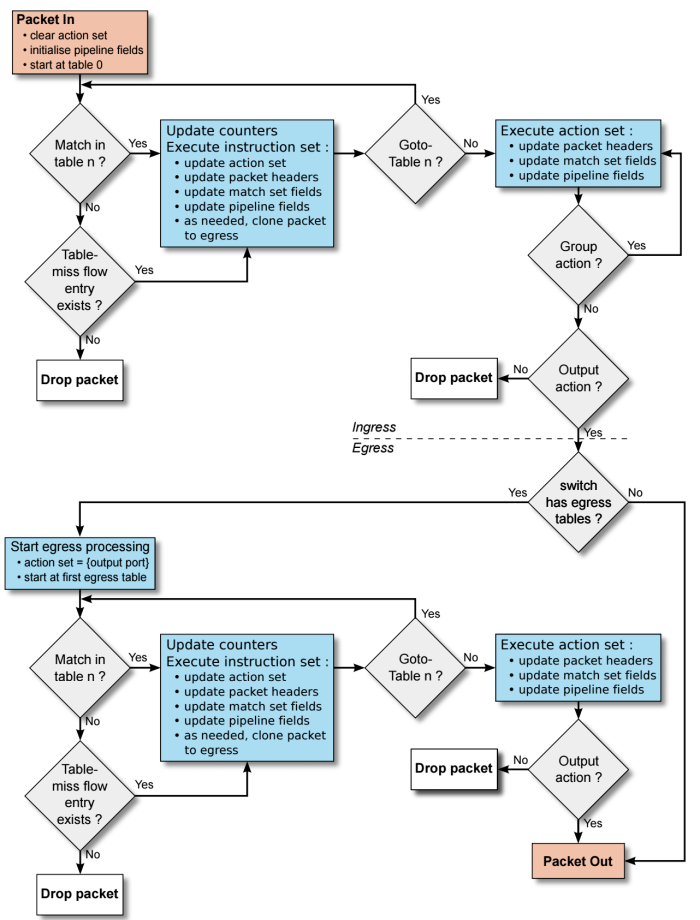
流水线处理
流表在处理时,就像流水线一下,每个 table 都是一个处理阶段。在每一个 table 里,数据包都可能被:
- 丢弃。
- 转发给下一个 table
- 发送给 controller
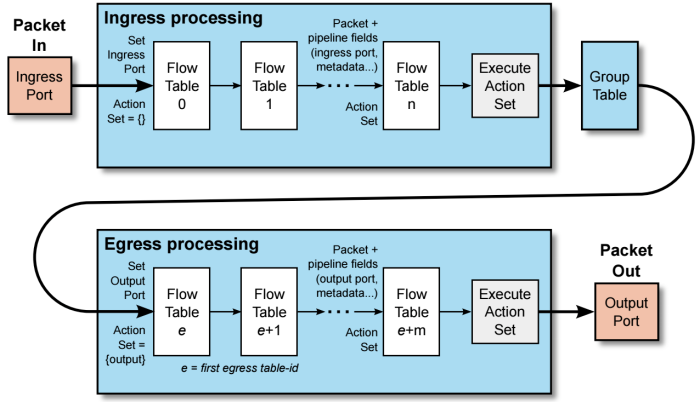
如上图所示,数据包通过 port 进入交换机后,首先会匹配 table 0 中的流表项。如果流表项匹配到了,则会根据该流表项设定的 actions 进行操作。如果未匹配到,则会被丢弃。
数据包在不同的 table 中流转时,只能按照升序进行,也就是说可以从 table 0 → table10,但是不能从 table10 → table0。并且需要注意的是,在流表之间跳转需要使用 goto_table 或 resubmit 语句来将数据包 copy 一份转发到其他的流表中处理。如果没有指定跳转动作,是不会继续在其他 table 中进行匹配的。
OVS 操作演示
为了加深对 OpenFlow 的理解,可以使用 OVS 提供的一个例子进行练习。这个例子中,使用 OVS 的流表实现了交换机二层 Mac 地址的学习,以及 VLAN 的支持。
环境准备
和 ovs 官网不同的是,这里我使用 mininet 快速创建一个实验环境。
sudo mn --topo=single,4 --mac --controller=none
这里创建了一个名为 s1 的交换机和 4 台连接到交换机上的主机 h1, h2, h3, h4,通过 port1, port2, port3, port4 连接。port1 trunk 所有的 vlan,port2 access vlan 20, port3, port3 access vlan 30。
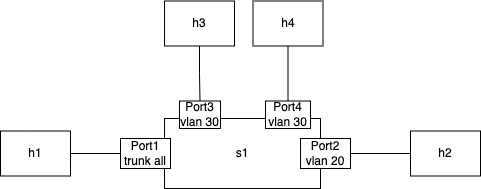
table 0: 准入控制
table 0 是数据包进入交换机的起始位置。我们在这一步去禁止某些数据包的进入。比如:以多播源地址的数据包是非法的,所以我们可以在这里丢弃掉。
sh ovs-ofctl add-flow s1 "table=0, dl_src=01:00:00:00:00:00/01:00:00:00:00:00, actions=drop"
交换机也不应该转发 IEEE 802.1D Spanning Tree Protocol(STP) 数据包,所以我们在可以通过流表项来丢弃掉。
sh ovs-ofctl add-flow s1 "table=0, dl_dst=01:80:c2:00:00:00/ff:ff:ff:ff:ff:f0, actions=drop"
对于其他合法的数据包,我们都提交到流水线的下一阶段(table1) 中去处理。这里我们使用最低的优先级来做兜底
sh ovs-ofctl add-flow s1 "table=0, priority=0, actions=resubmit(,1)"
测试 table 0
这里因为有一些数据包不方便构造去做实际的测试,所以使用 ofproto/trace 去模拟数据库的匹配。
例子1
sh ovs-appctl ofproto/trace s1 in_port=1,dl_dst=01:80:c2:00:00:05
会出现以下输出
Flow: in_port=1,vlan_tci=0x0000,dl_src=00:00:00:00:00:00,dl_dst=01:80:c2:00:00:05,dl_type=0x0000
bridge("s1")
------------
0. dl_dst=01:80:c2:00:00:00/ff:ff:ff:ff:ff:f0, priority 32768
drop
Final flow: unchanged
Megaflow: recirc_id=0,eth,in_port=1,dl_src=00:00:00:00:00:00/01:00:00:00:00:00,dl_dst=01:80:c2:00:00:00/ff:ff:ff:ff:ff:f0,dl_type=0x0000
Datapath actions: drop
可以看到以下关键信息:
- 数据包匹配到了
dl_dst=01:80:c2:00:00:00/ff:ff:ff:ff:ff:f0, priority 32768 ,根据 action 需要被 drop 掉
- Final flow 为 unchanged ,说明数据包本身没有被修改。
例子2
sh ovs-appctl ofproto/trace s1 in_port=1,dl_dst=01:80:c2:00:00:10
出现以下输出
Flow: in_port=1,vlan_tci=0x0000,dl_src=00:00:00:00:00:00,dl_dst=01:80:c2:00:00:10,dl_type=0x0000
bridge("s1")
------------
0. priority 0
resubmit(,1)
1. No match.
drop
Final flow: unchanged
Megaflow: recirc_id=0,eth,in_port=1,dl_src=00:00:00:00:00:00/01:00:00:00:00:00,dl_dst=01:80:c2:00:00:10/ff:ff:ff:ff:ff:f0,dl_type=0x0000
Datapath actions: drop
可以看出数据包被 resubmit 到 table 1 了,但是因为 table 1 中没有任何流表项,所以被 drop 了。
table 1: VLAN 进入数据包处理
进入 table 1 的数据包,都是在 table 0 中被校验有效的数据包。table 1 被设计用来校验数据包的 VLAN,这个校验是基于数据包进入交换机经过的 Port 配置。同时我们也会在这些进入 access port 的数据包 header 里添加 VLAN tag,来保证后续的处理都可以基于这些 VLAN tag 进行。
首先我们添加一个默认 drop 的规则
sh ovs-ofctl add-flow s1 "table=1, priority=0, actions=drop"
对于 trunk port 1,可以接收任意数据包,无论数据包是否有 VLAN header 或者这个 VLAN tag 是多少。所以可以添加一个流表项,将进入 port1 的所有数据包 resubmit 到 table 2 中。
sh ovs-ofctl add-flow s1 "table=1, priority=99, in_port=1, actions=resubmit(,2)"
在 access port 上,只接收没有 VLAN header 的数据包,然后对数据包打上 VLAN tag,然后再提交到下一阶段(table2) 去处理。
sh ovs-ofctl add-flow s1 "table=1, priority=99, in_port=2, vlan_tci=0, actions=mod_vlan_vid:20, resubmit(,2)"
sh ovs-ofctl add-flow s1 "table=1, priority=99, in_port=3, vlan_tci=0, actions=mod_vlan_vid:30, resubmit(,2)"
sh ovs-ofctl add-flow s1 "table=1, priority=99, in_port=4, vlan_tci=0, actions=mod_vlan_vid:30, resubmit(,2)"
测试 table 1
例子1:数据包进入 trunk port
数据包进入 trunk port 1
sh ovs-appctl ofproto/trace s1 in_port=1,vlan_tci=5
得到以下输出,数据包在 table 0 中 resubmit 到 table 1,再到 table 2 后没有规则,被默认丢弃
Flow: in_port=1,vlan_tci=0x0005,vlan_tci1=0x0000,dl_src=00:00:00:00:00:00,dl_dst=00:00:00:00:00:00,dl_type=0x0000
bridge("s1")
------------
0. priority 0
resubmit(,1)
1. in_port=1, priority 99
resubmit(,2)
2. No match.
drop
Final flow: unchanged
Megaflow: recirc_id=0,eth,in_port=1,dl_src=00:00:00:00:00:00/01:00:00:00:00:00,dl_dst=00:00:00:00:00:00/ff:ff:ff:ff:ff:f0,dl_type=0x0000
Datapath actions: drop
例子2:有效的数据包进入 access port
一个没有 802.1Q header 的数据包进入 port 2
sh ovs-appctl ofproto/trace s1 in_port=2
得到以下输出,数据包在 table 0 中 resubmit 到 table 1,再到 table 2 后没有规则,被默认丢弃i
Flow: in_port=2,vlan_tci=0x0000,dl_src=00:00:00:00:00:00,dl_dst=00:00:00:00:00:00,dl_type=0x0000
bridge("s1")
------------
0. priority 0
resubmit(,1)
1. in_port=2,vlan_tci=0x0000, priority 99
mod_vlan_vid:20
resubmit(,2)
2. No match.
drop
Final flow: in_port=2,dl_vlan=20,dl_vlan_pcp=0,vlan_tci1=0x0000,dl_src=00:00:00:00:00:00,dl_dst=00:00:00:00:00:00,dl_type=0x0000
Megaflow: recirc_id=0,eth,in_port=2,dl_src=00:00:00:00:00:00/01:00:00:00:00:00,dl_dst=00:00:00:00:00:00/ff:ff:ff:ff:ff:f0,dl_type=0x0000
Datapath actions: drop
例子3: 无效的数据包进入 access port
一个有 802.1Q header 的数据包进入 port 2
sh ovs-appctl ofproto/trace s1 in_port=2,vlan_tci=5
得到以下输出,在 table 1 中被 drop 了。
Flow: in_port=2,vlan_tci=0x0005,vlan_tci1=0x0000,dl_src=00:00:00:00:00:00,dl_dst=00:00:00:00:00:00,dl_type=0x0000
bridge("s1")
------------
0. priority 0
resubmit(,1)
1. priority 0
drop
Final flow: unchanged
Megaflow: recirc_id=0,eth,in_port=2,vlan_tci=0x0005,dl_src=00:00:00:00:00:00/01:00:00:00:00:00,dl_dst=00:00:00:00:00:00/ff:ff:ff:ff:ff:f0,dl_type=0x0000
Datapath actions: drop
table 2: 进入 port 后学习 MAC+VLAN
table 2允许我们实现的交换机学习数据包的 source mac。只需要一个流表项
sh ovs-ofctl add-flow s1 "table=2 actions=learn(table=10, NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[], load:NXM_OF_IN_PORT[]->NXM_NX_REG0[0..15]),resubmit(,3)"
learn 这个 action 会基于正在处理的数据包,动态的修改流表。对于 learn 的几个字段说明如下:
table=10
Modify flow table 10. This will be the MAC learning table.
NXM_OF_VLAN_TCI[0..11]
Make the flow that we add to flow table 10 match the same VLAN
ID that the packet we're currently processing contains. This
effectively scopes the MAC learning entry to a single VLAN,
which is the ordinary behavior for a VLAN-aware switch.
NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[]
Make the flow that we add to flow table 10 match, as Ethernet
destination, the Ethernet source address of the packet we're
currently processing.
load:NXM_OF_IN_PORT[]->NXM_NX_REG0[0..15]
Whereas the preceding parts specify fields for the new flow to
match, this specifies an action for the flow to take when it
matches. The action is for the flow to load the ingress port
number of the current packet into register 0 (a special field
that is an Open vSwitch extension to OpenFlow).
测试 table 2
例子1
sh ovs-appctl ofproto/trace s1 in_port=1,vlan_tci=20,dl_src=50:00:00:00:00:01 -generate
得到以下输出。上面的命令中使用了 -generate,是为了让数据包真实的在 OVS 中生效,不指定的话,OVS 不会真实的生成 table 10 中的流表项。
Flow: in_port=1,vlan_tci=0x0014,vlan_tci1=0x0000,dl_src=50:00:00:00:00:01,dl_dst=00:00:00:00:00:00,dl_type=0x0000
bridge("s1")
------------
0. priority 0
resubmit(,1)
1. in_port=1, priority 99
resubmit(,2)
2. priority 32768
learn(table=10,NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:NXM_OF_IN_PORT[]->NXM_NX_REG0[0..15])
-> table=10 vlan_tci=0x0014/0x0fff,dl_dst=50:00:00:00:00:01 priority=32768 actions=load:0x1->NXM_NX_REG0[0..15]
resubmit(,3)
3. No match.
drop
Final flow: unchanged
Megaflow: recirc_id=0,eth,in_port=1,vlan_tci=0x0014/0x1fff,dl_src=50:00:00:00:00:01,dl_dst=00:00:00:00:00:00/ff:ff:ff:ff:ff:f0,dl_type=0x0000
Datapath actions: drop
在 table 10 中确认是否有新的流表项生成
sh ovs-ofctl dump-flows s1 table=10
cookie=0x0, duration=142.170s, table=10, n_packets=0, n_bytes=0, vlan_tci=0x0014/0x0fff,dl_dst=50:00:00:00:00:01 actions=load:0x1->NXM_NX_REG0[0..15]
例子2
sh ovs-appctl ofproto/trace s1 in_port=2,dl_src=50:00:00:00:00:01 -generate
cookie=0x0, duration=193.493s, table=10, n_packets=0, n_bytes=0, vlan_tci=0x0014/0x0fff,dl_dst=50:00:00:00:00:01 actions=load:0x2->NXM_NX_REG0[0..15]
可以看到,在例子 1 中 table 10 中,在 port 1 上学习到了 mac 地址 50:00:00:00:00:01,现在 port 2 中也出现了该 mac 地址,所以这个 mac 地址更新到了 port 2 上。
table 3: 查找目标 Port
这个 table 实现了如何通过 MAC 和 VLAN 查找到目标的 output port。通过以下流表项来实现查找
sh ovs-ofctl add-flow s1 "table=3 priority=50 actions=resubmit(,10), resubmit(,4)"
这个流表项首先将数据包提交到 table 10 中。table 10 中存储了学习到的 mac 地址。如果这个 mac 地址没有被学习过,则 table 10 中不会被匹配。那么就会被 resubmit 到 table 4 中继续处理。
测试 table 3
下面的命令会让 OVS 学习到 port 1上 VLAN 20 的 mac 地址 f0:00:00:00:00:01
sh ovs-appctl ofproto/trace s1 in_port=1,dl_vlan=20,dl_src=f0:00:00:00:00:01,dl_dst=90:00:00:00:00:01 -generate
得到以下输出,数据包在 table 10 中没有匹配到,所以被 resubmit 到 table 4.
Flow: in_port=1,dl_vlan=20,dl_vlan_pcp=0,vlan_tci1=0x0000,dl_src=f0:00:00:00:00:01,dl_dst=90:00:00:00:00:01,dl_type=0x0000
bridge("s1")
------------
0. priority 0
resubmit(,1)
1. in_port=1, priority 99
resubmit(,2)
2. priority 32768
learn(table=10,NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:NXM_OF_IN_PORT[]->NXM_NX_REG0[0..15])
-> table=10 vlan_tci=0x0014/0x0fff,dl_dst=f0:00:00:00:00:01 priority=32768 actions=load:0x1->NXM_NX_REG0[0..15]
resubmit(,3)
3. priority 50
resubmit(,10)
10. No match.
drop
resubmit(,4)
4. No match.
drop
Final flow: unchanged
Megaflow: recirc_id=0,eth,in_port=1,dl_vlan=20,dl_src=f0:00:00:00:00:01,dl_dst=90:00:00:00:00:01,dl_type=0x0000
Datapath actions: drop
可以通过以下两种方式验证 port 1 上学习到的 mac 地址:
方法一:
sh ovs-ofctl dump-flows s1 table=10
cookie=0x0, duration=107.451s, table=10, n_packets=0, n_bytes=0, vlan_tci=0x0014/0x0fff,dl_dst=f0:00:00:00:00:01 actions=load:0x1->NXM_NX_REG0[0..15]
方法二:
sh ovs-appctl ofproto/trace s1 in_port=2,dl_src=90:00:00:00:00:01,dl_dst=f0:00:00:00:00:01 -generate
Flow: in_port=2,vlan_tci=0x0000,dl_src=90:00:00:00:00:01,dl_dst=f0:00:00:00:00:01,dl_type=0x0000
bridge("s1")
------------
0. priority 0
resubmit(,1)
1. in_port=2,vlan_tci=0x0000, priority 99
mod_vlan_vid:20
resubmit(,2)
2. priority 32768
learn(table=10,NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:NXM_OF_IN_PORT[]->NXM_NX_REG0[0..15])
-> table=10 vlan_tci=0x0014/0x0fff,dl_dst=90:00:00:00:00:01 priority=32768 actions=load:0x2->NXM_NX_REG0[0..15]
resubmit(,3)
3. priority 50
resubmit(,10)
10. vlan_tci=0x0014/0x0fff,dl_dst=f0:00:00:00:00:01, priority 32768
load:0x1->NXM_NX_REG0[0..15]
resubmit(,4)
4. No match.
drop
Final flow: reg0=0x1,in_port=2,dl_vlan=20,dl_vlan_pcp=0,vlan_tci1=0x0000,dl_src=90:00:00:00:00:01,dl_dst=f0:00:00:00:00:01,dl_type=0x0000
Megaflow: recirc_id=0,eth,in_port=2,dl_src=90:00:00:00:00:01,dl_dst=f0:00:00:00:00:01,dl_type=0x0000
Datapath actions: drop
可以看到在 table 10 中匹配到了流表项,学习到了 load:0x1->NXM_NX_REG0[0..15]
table 4: 数据包输出处理
在 table 4 中,我们知道 register 0 包含了需要的 output port,如果该 output port 是 0,则说明需要将数据包 flood。我们也知道数据包的 VLAN 在它的 802.1Q header 上。
sh ovs-ofctl add-flow s1 "table=4 reg0=1 actions=1"
对于要 output 的 port,还需要把 VLAN header 移除掉。
sh ovs-ofctl add-flow s1 "table=4 reg0=2 actions=strip_vlan,2"
sh ovs-ofctl add-flow s1 "table=4 reg0=3 actions=strip_vlan,3"
sh ovs-ofctl add-flow s1 "table=4 reg0=4 actions=strip_vlan,4"
flood 广播或多播包
sh ovs-ofctl add-flow s1 "table=4 reg0=0 priority=99 dl_vlan=20 actions=1,strip_vlan,2"
sh ovs-ofctl add-flow s1 "table=4 reg0=0 priority=99 dl_vlan=30 actions=1,strip_vlan,3,4"
sh ovs-ofctl add-flow s1 "table=4 reg0=0 priority=50 actions=1"
测试 table 4
例子1:广播,多播以及未知目的地址
测试在 port 1 上进入广播包,VLAN 是 30
sh ovs-appctl ofproto/trace s1 in_port=1,dl_dst=ff:ff:ff:ff:ff:ff,dl_vlan=30
Flow: in_port=1,dl_vlan=30,dl_vlan_pcp=0,vlan_tci1=0x0000,dl_src=00:00:00:00:00:00,dl_dst=ff:ff:ff:ff:ff:ff,dl_type=0x0000
bridge("s1")
------------
0. priority 0
resubmit(,1)
1. in_port=1, priority 99
resubmit(,2)
2. priority 32768
learn(table=10,NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:NXM_OF_IN_PORT[]->NXM_NX_REG0[0..15])
>> suppressing side effects, so learn action ignored
resubmit(,3)
3. priority 50
resubmit(,10)
10. No match.
drop
resubmit(,4)
4. reg0=0,dl_vlan=30, priority 99
output:1
>> skipping output to input port
strip_vlan
output:3
output:4
Final flow: in_port=1,vlan_tci=0x0000,dl_src=00:00:00:00:00:00,dl_dst=ff:ff:ff:ff:ff:ff,dl_type=0x0000
Megaflow: recirc_id=0,eth,in_port=1,dl_vlan=30,dl_vlan_pcp=0,dl_src=00:00:00:00:00:00,dl_dst=ff:ff:ff:ff:ff:ff,dl_type=0x0000
Datapath actions: pop_vlan,4,3
可以看到 Datapath actions: pop_vlan,4,3,最终数据包被移除 vlan,从 port3,4出去了。
而下面的广播包都会被 drop,因为 VLAN 必须属于 input port
sh ovs-appctl ofproto/trace s1 in_port=1,dl_dst=ff:ff:ff:ff:ff:ff
sh ovs-appctl ofproto/trace s1 in_port=1,dl_dst=ff:ff:ff:ff:ff:ff,dl_vlan=55
例子2: MAC 学习
VLAN 30, port 1 学习 MAC 地址:
sh ovs-appctl ofproto/trace s1 in_port=1,dl_vlan=30,dl_src=10:00:00:00:00:01,dl_dst=20:00:00:00:00:01 -generate
Flow: in_port=1,dl_vlan=30,dl_vlan_pcp=0,vlan_tci1=0x0000,dl_src=10:00:00:00:00:01,dl_dst=20:00:00:00:00:01,dl_type=0x0000
bridge("s1")
------------
0. priority 0
resubmit(,1)
1. in_port=1, priority 99
resubmit(,2)
2. priority 32768
learn(table=10,NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:NXM_OF_IN_PORT[]->NXM_NX_REG0[0..15])
-> table=10 vlan_tci=0x001e/0x0fff,dl_dst=10:00:00:00:00:01 priority=32768 actions=load:0x1->NXM_NX_REG0[0..15]
resubmit(,3)
3. priority 50
resubmit(,10)
10. No match.
drop
resubmit(,4)
4. reg0=0,dl_vlan=30, priority 99
output:1
>> skipping output to input port
strip_vlan
output:3
output:4
Final flow: in_port=1,vlan_tci=0x0000,dl_src=10:00:00:00:00:01,dl_dst=20:00:00:00:00:01,dl_type=0x0000
Megaflow: recirc_id=0,eth,in_port=1,dl_vlan=30,dl_vlan_pcp=0,dl_src=10:00:00:00:00:01,dl_dst=20:00:00:00:00:01,dl_type=0x0000
Datapath actions: pop_vlan,4,3
因为目的地址是未知的,所以数据包被 flood 到 port3,port4 上。然后我们再次测试 MAC 地址是否学习到了。
sh ovs-appctl ofproto/trace s1 in_port=4,dl_src=20:00:00:00:00:01,dl_dst=10:00:00:00:00:01 -generate
Flow: in_port=4,vlan_tci=0x0000,dl_src=20:00:00:00:00:01,dl_dst=10:00:00:00:00:01,dl_type=0x0000
bridge("s1")
------------
0. priority 0
resubmit(,1)
1. in_port=4,vlan_tci=0x0000, priority 99
mod_vlan_vid:30
resubmit(,2)
2. priority 32768
learn(table=10,NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:NXM_OF_IN_PORT[]->NXM_NX_REG0[0..15])
-> table=10 vlan_tci=0x001e/0x0fff,dl_dst=20:00:00:00:00:01 priority=32768 actions=load:0x4->NXM_NX_REG0[0..15]
resubmit(,3)
3. priority 50
resubmit(,10)
10. vlan_tci=0x001e/0x0fff,dl_dst=10:00:00:00:00:01, priority 32768
load:0x1->NXM_NX_REG0[0..15]
resubmit(,4)
4. reg0=0x1, priority 32768
output:1
Final flow: reg0=0x1,in_port=4,dl_vlan=30,dl_vlan_pcp=0,vlan_tci1=0x0000,dl_src=20:00:00:00:00:01,dl_dst=10:00:00:00:00:01,dl_type=0x0000
Megaflow: recirc_id=0,eth,in_port=4,dl_src=20:00:00:00:00:01,dl_dst=10:00:00:00:00:01,dl_type=0x0000
Datapath actions: push_vlan(vid=30,pcp=0),2