概述
Linux 作为最流行的服务器操作系统,其提供的网络能力也是经过了各种各样场景的考验。因此如果经常和 linux server 打交道的话,了解 linux 的数据包处理流程也是很有必要的。
网络数据包的接收处理可以分成两个部分,一是从物理网卡进入到达 linux 内核的网络协议栈,二是经网络协议栈处理后交给上层应用或者转发出去。本篇文档主要说明第一部分,并且不会去深入细节点(因为我也不太熟)。
重要概念和数据结构
在说明网络数据包的处理流程之前,有必要提前讲一下一些相关的概念,因为这些概念决定了后面的内容是否能够理解。
硬中断
硬中断是由硬件在发生某些事件后发出的,称为中断请求(IRQ),CPU 会响应硬中断,并执行对应的 IRQ Handler。对于网卡来说,在有网络流量进入后,网卡会通过硬中断通知 CPU 有网络流量进来了,CPU 会调用对应网卡驱动中的处理函数。
硬中断在处理期间,是屏蔽外部中断的,所以硬中断的处理时间要尽可能的短。
软中断
软中断是由软件执行指令发出的,因为硬中断的特点不能处理耗时的任务,所以软中断往往用来替代硬中断来处理耗时任务。
比如网络流量的处理,网卡在发出硬中断通知 CPU 处理后,这次硬中断的处理方法中又会触发软中断,由软中断接着去处理网络流量数据。
网卡驱动
驱动是打通硬件和操作系统的通道,linux 通过网卡驱动,可以支持不同厂商,不同型号,不同特性的网卡。网卡驱动主要负责将从网卡中进来的流量解析并转换成 sk_buff,交给内核协议栈。
DMA
DMA是一种无需CPU的参与就可以让外设和系统内存之间进行双向数据传输的硬件机制。网卡会通过 DMA 直接将网络流量数据存储到一块提前申请好的内存区域中。
NAPI
全称 New API,因为没有更好的名字,所以就直接用 NAPI 了。这是用于支持高速网卡处理网络数据包的一种机制。非 NAPI 往往是只依靠硬中断的方式让 CPU 来处理数据包,NAPI 引入了硬中断+轮询的方式,有效的缓解了硬中断带来的性能问题。
sk_buff
sk_buff 是一个非常大而通用的 struct,可以用来表示2,3,4层的数据包。它被分成两个部分:head 和 data。
head 部分有单独的字段表示不同层的网络头:
- transport_header:用来表示传输层(4层)的 header,包括 tcp, udp, icmp 等协议头
- network_header:用来表示网络层(3层)的 header,包括 ip, ipv6, arp 等协议头
- mac_header:用来表示链路层(2层)的 header。
当数据包进入网络协议栈之前,需要先被转换成 sk_buff。
流程梳理
数据包进入触发硬中断
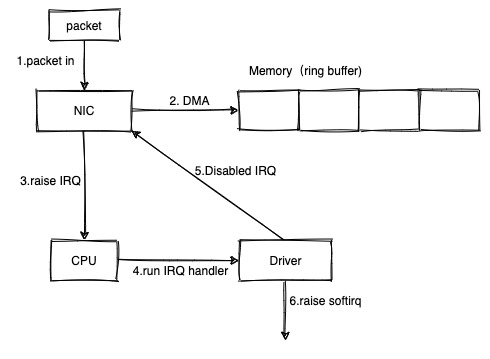
- 数据包进入网卡设备
-
网卡设备通过 DMA 直接写入的内存中。如果写不下就直接 drop 掉
-
网卡产生硬中断
-
CPU 收到硬中断后,会直接提前注册好的该硬中断的 handler。这个 handler 是写在网卡驱动中的一个方法
-
IRQ handler 禁用网卡的 IRQ。这是后面处理内存中的数据包是采用的 poll 模式。也就是说 cpu 会自己去内存中轮询数据包,直到一定时间/数量,或者全部处理完之后。这段时间内就不需要网卡通过硬中断来通知 CPU 了,并且硬中断会打断 CPU 的工作,带来一定的性能问题。
-
网卡驱动产生软中断。
软中断触发数据包的处理
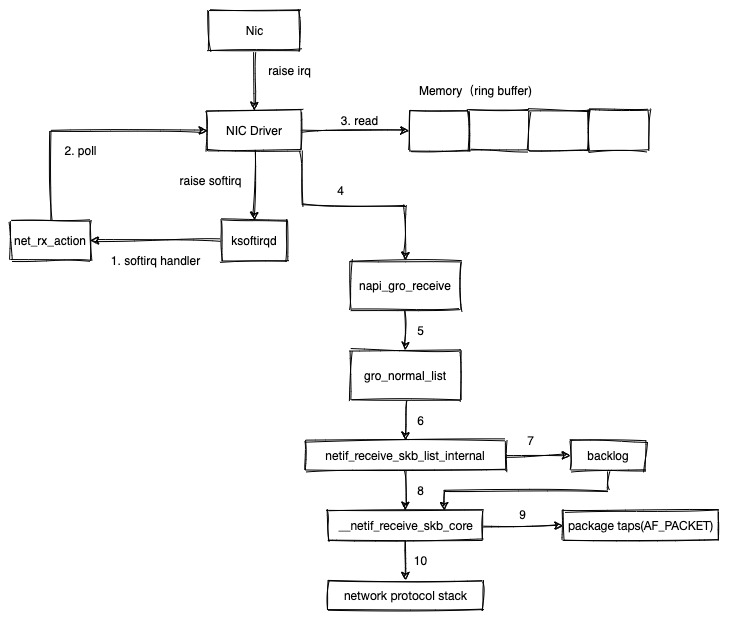
这里为了方便表述,使用目前最常用的 NAPI 的处理流程进行说明。
- 在系统启动时,net_dev_init 方法中注册了 NET_RX_SOFTIRQ 对应的 handler 是 net_rx_action。上面触发软中断的方式是 __raise_softirq_irqoff(NET_RX_SOFTIRQ)。所以开始执行 net_rx_action
- net_rx_action 会从 poll_list 链表中获取第一个 poll,使用 napi_poll 轮询内存中的数据包。napi_poll 调用到网卡驱动提供的 poll 方法
- poll 方法中从内存中取出数据包
- 网卡驱动调用 napi_gro_receive 来处理数据包
- napi gro 会合并多个 skb 数据包,比如一个 IP 包会被分成多个 frame 这种。那么如果在接收的时候,在到达协议栈之前直接合并,会有一定的性能提升。这里最终会调用到 gro_normal_list 来批量处理 skb。
- 最终调用到 netif_receive_skb_list_internal,从 napi.rx_list 上处理 sk_buff 链表。
- 如果开启了 RPS,会根据 skb 的 hash 值找到对应的 cpu,将 skb 存储到该 cpu 上的 backlog 队列。backlog 队列是一种用软件方式将数据包处理负载均衡到多个 cpu 上的一种方法。
- 最终都会调用到 __netif_receive_skb_core。
- 如果有 AF_PACKET 的 socket,还会拷贝一份给它(tcpdump 的实现原理)。
- 最后递交给内核协议栈
参考
Monitoring and Tuning the Linux Networking Stack: Receiving Data
《linux 网络数据包接收流程(一)》上有1条评论