简介
linux 下的 ip 命令是一个很强大的工具,在这之前,我通常只会使用 ifconfig 命令来查看本机网络接口和 ip 地址等等。或者 netstat 命令查看端口占用等等。ip 命令属于 iproute2 套件中的一个命令,关于 iproute2 和 linux net-tools 中的命令对比如下(图片来源:https://linux.cn/article-3144-1.html):
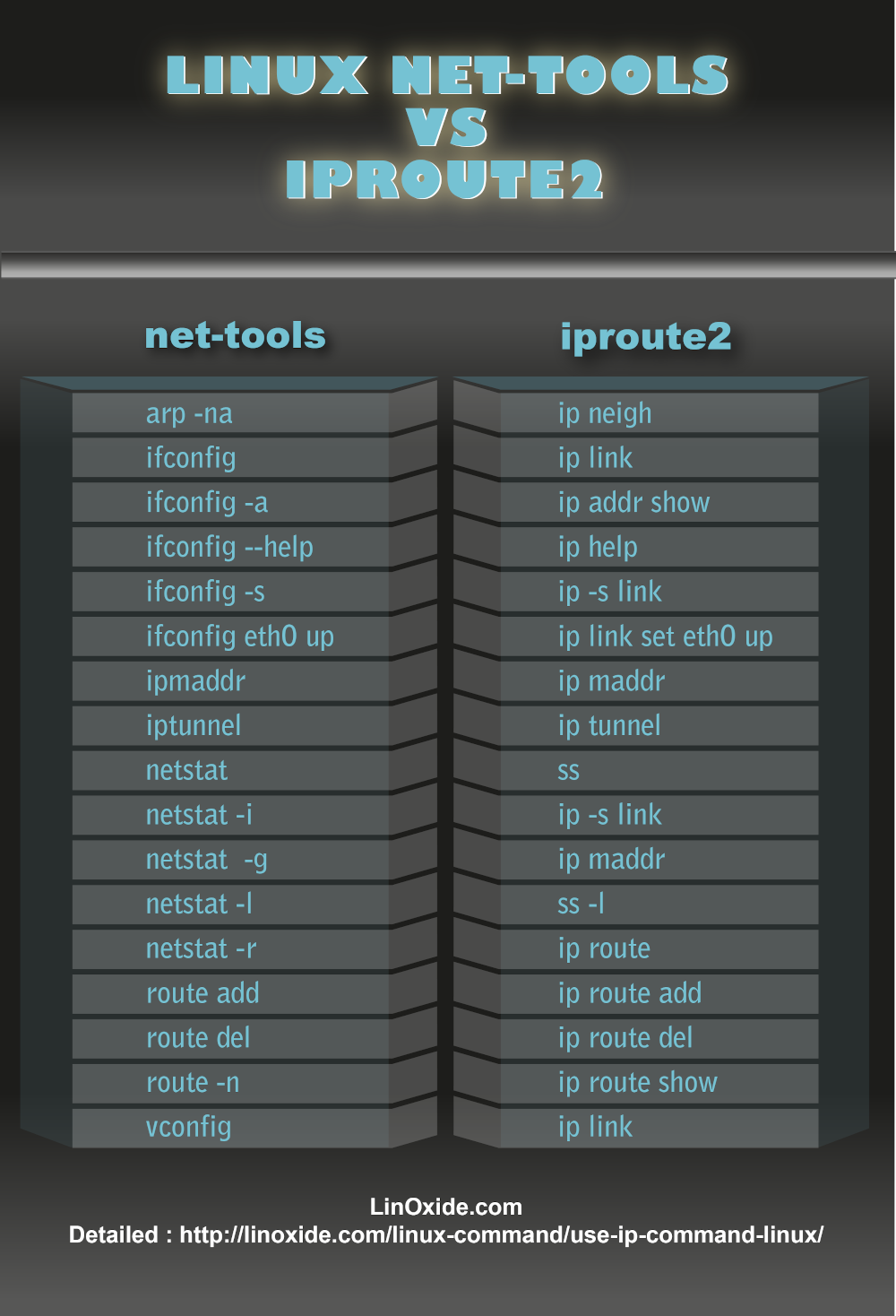
可以看出,除了部分 netstat 命令用 ss 来替代,其它都可以用 ip 命令替代。并且,iproute2 已经是大多数 linux 发行版默认安装了,而 net-tools 则需要另外安装。
ip 命令可以分为下面几个模块:
- 网卡设备相关:
ip link - 网卡地址相关:
ip addr - 路由表相关:
ip route - arp 相关:
ip neigh
下面会列出一些常用的操作,最好在虚拟机中操作,防止影响个人机器。
ip link
查看 ip link 的帮助
$ ip link help
查看网络接口
$ ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:8a:fe:e6 brd ff:ff:ff:ff:ff:ff
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:15:ee:5c brd ff:ff:ff:ff:ff:ff
这里显示了三个网络接口,lo代表的本机的回环网卡,eth0 和 eth1 分别是两个网卡
添加网络接口
$ sudo ip link add link eth0 mydev type bridge
这里添加了一个网桥,连接在 eth0 上。使用 ip link list 查看可以发现多了下面一个设备
6: mydev: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 5e:0c:36:7b:ce:0d brd ff:ff:ff:ff:ff:ff
删除网络接口
$ sudo ip link delete link dev mydev
关闭网络接口
$ sudo ip link set eth1 down
打开网络接口
$ sudo ip link set eht1 up
ip addr
查看帮助
$ ip addr help
查看网络地址
$ ip addr list
查看某一个网络接口的地址
$ ip addr show eth1
添加 ip 地址
$ sudo ip addr add 192.168.31.131/24 dev eth1
查看 eth1 的地址
$ ip addr show eth1
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:15:ee:5c brd ff:ff:ff:ff:ff:ff
inet 192.168.31.77/24 brd 192.168.31.255 scope global noprefixroute dynamic eth1
valid_lft 42769sec preferred_lft 42769sec
inet 192.168.31.131/24 scope global secondary eth1
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fe15:ee5c/64 scope link
valid_lft forever preferred_lft forever
我们也可以 ping 一下这个地址:
$ ping 192.168.31.131
PING 192.168.31.131 (192.168.31.131) 56(84) bytes of data.
64 bytes from 192.168.31.131: icmp_seq=1 ttl=64 time=0.109 ms
64 bytes from 192.168.31.131: icmp_seq=2 ttl=64 time=0.155 ms
删除 ip 地址
$ sudo ip addr del 192.168.31.131/24 dev eth1
改变设备地址的配置
这里有一篇很好的文章: understanding ip addr change and ip addr replace commands
为了演示的方便,我添加了一个网卡设备
$ sudo ip link add link eth0 name dummy0 type dummy
为它分配地址:
$ sudo ip addr add 192.168.31.132/24 dummy0
$ ip addr show dummy0
5: dummy0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 9e:dc:6e:0b:70:99 brd ff:ff:ff:ff:ff:ff
inet 192.168.31.132/24 scope global dummy0
valid_lft forever preferred_lft forever
如果你想要修改 valid_lft 和 preferred_lft 配置,可以使用 ip change命令:
$ sudo ip addr change 192.168.31.132 dev dummy0 preferred_lft 300 valid_lft 300
$ ip addr show dummpy0
5: dummy0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 9e:dc:6e:0b:70:99 brd ff:ff:ff:ff:ff:ff
inet 192.168.31.132/24 scope global dynamic dummy0
valid_lft 299sec preferred_lft 299sec
ip route
查看帮助
$ ip route help
查看路由
$ ip route list
添加路由
添加一条普通的路由
$ sudo ip route add 39.156.0.0/16 via 192.168.31.133 dev dummy0
添加默认路由
$ sudo ip route add default via 192.168.31.133 dev dummy0
删除路由
删除默认路由
$ sudo ip route del default via 192.168.31.133 dev dummy0
删除普通路由
$ sudo ip route del 39.156.0.0/16 via 192.168.31.133 dev dummy0
**查看一个 ip 地址的路由包来源
$ ip route get 39.156.69.79
39.156.69.79 via 10.0.2.2 dev eth0 src 10.0.2.15
cache
ip neigh
查看帮助
$ ip neigh help
查看同一个网络的邻居设备
$ ip neigh show
192.168.31.1 dev eth1 lladdr 34:ce:00:2e:88:b9 STALE
10.0.2.2 dev eth0 lladdr 52:54:00:12:35:02 REACHABLE
10.0.2.3 dev eth0 lladdr 52:54:00:12:35:03 STALE