一、概述
一个运行中的 kubernetes 集群,存储了非常多的相互关联的资源,比如我们常用的 deployment,replicaset 和 pod,就是一组有关联的资源。我们在创建 deployment 时,相关的控制器就会自动创建出 replicaset,之后 replicaset 的控制器又会创建出 pod 来运行我们部署的服务。那么同样的,我们肯定也希望在删除 deployment 之后,会自动删除 replicaset 和 pod。这个机制就叫做垃圾回收(下面简称 GC)。
在早期的版本中,GC 是由客户端实现的,比如使用 kubectl delete deployment nginx 这样的命令,kubectl 会删除 pod 和 replicaset。但是这种方式增加了客户端的实现复杂度,不利于统一管理。因此提出了在服务端实现 GC 的需求。实现 GC 有三个主要目标,我们在之后分析的时候,也主要是围绕这三个主要目标进行。
- 在服务端支持级联删除
- 中心化级联删除的逻辑,而不是分布在各个组件内
- 可以选择不删除被依赖的资源。如只删除 deployment,但是保留 replicaset 和 pod
kubernetes 的 GC 是在 controller manager 中,作为一个单独的 controller 来实现的。它通过 discovery client 来动态发现并监听集群中所有支持 delete,list和watch的资源。然后构造资源之间的关系图来记录资源之间的依赖关系。
二、预备知识
为了更好的阐述 kubernetes 的 GC 机制,这里先将一些 k8s 基本知识做一些阐述。
- finalizer: finalizer 可以翻译为终结期。是一种用来保证资源在被删除之前,能够有机会做一些清理工作的机制。
- kubernetes 的删除传播策略有三种:
- Orphan. 这种策略下,会保留被依赖的资源。如只删除 deployment,但是保留 replicaset 和 pod。
- Background. 从 etcd 中删除资源,被依赖的资源由 GC 机制来删除。
- Foreground. apiserver 不会删除该资源。而是在它的 finalizer 中添加 foregroundDeletion,并且设置当前的删除时间戳。然后 GC 会先从 etcd 中删除有
ownerReference.blockOwnerDeletion=true的被依赖资源。最后再删除当前资源。
- UID。k8s 中的每个资源都有一个唯一的 UID。这个 UID 在整个集群的生命周期中,对于每一个资源来说都是唯一的。所有在标记资源的依赖关系时,需要使用 UID。
- ownerReferences。每个资源的 metadata 中都会有这个字段,它是一个数组,用来表示该资源的 owner 有哪些。每当 owner 资源被删除,就会从这个数组中移除。当所有的 owner 都被删除后,GC 就会回收该资源。
- Dependents。如果一组资源 G 的 ownerReference 指向某个具体的资源 A。那个 A 的 dependents 就是 G
三、垃圾回收的实现机制
kubernetes 的 GC 主要由两部分组成:
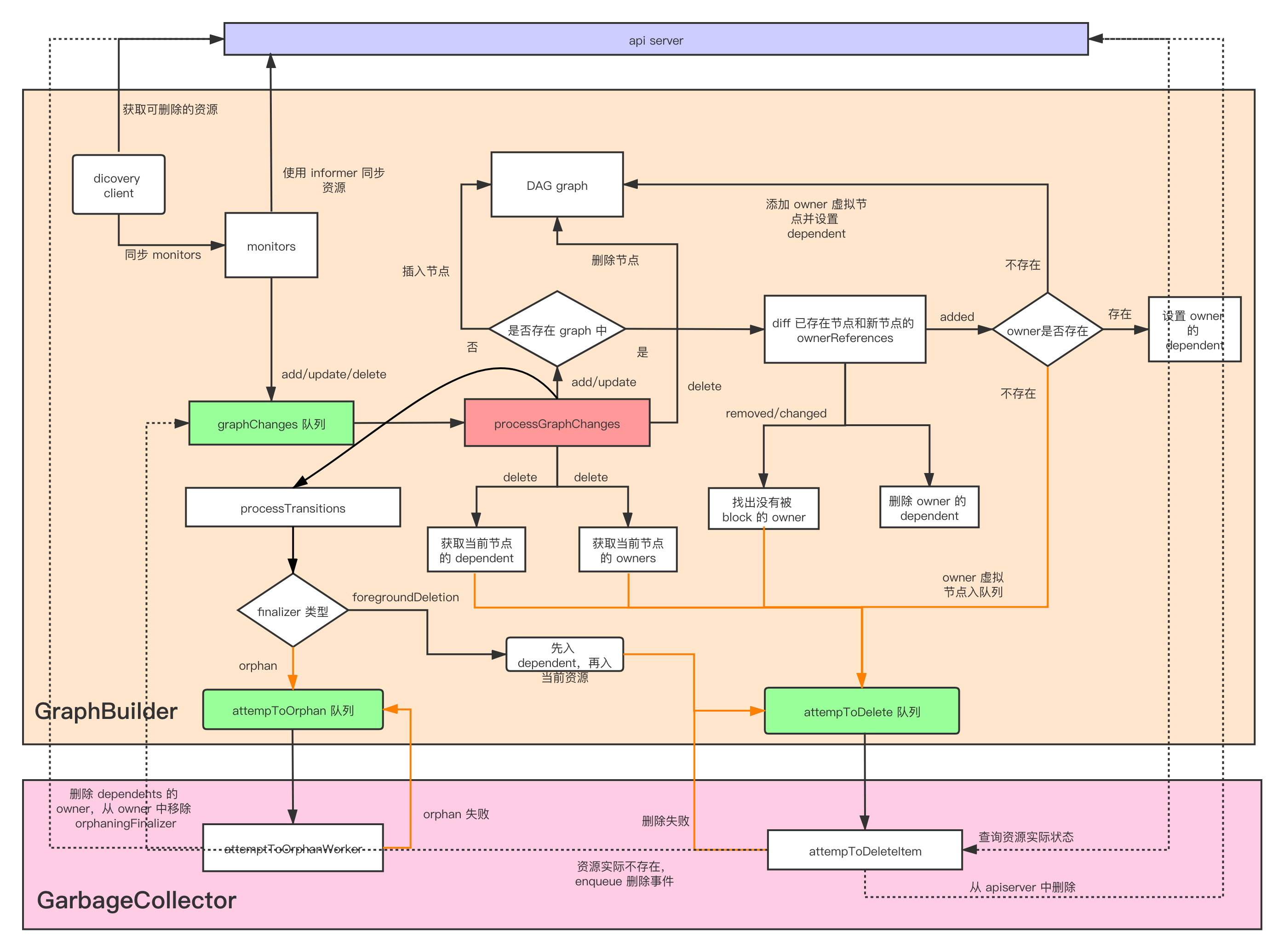
- GraphBuilder 主要用来使用 monitors 监听 apiserver 上的所有资源,通过将所有资源的事件插入到 graphChanges 队列中,然后调用
processGraphChanges方法,从队列中依次取出元素,构建资源之间的依赖关系。并根据情况插入到 attemptToDelete 或 attemptToOrphan 队列中。 - GarbageCollector 负责从 attemptToDelete 和 attemptToOrphan 队列中取出资源,然后通过一系列负责的过程,判断是否能删除,并进行相关的处理。
因此,对于垃圾回收实现机制的分析,主要从这两部分进行。
3.1 graph builder 的实现
graph builder 可以看做是集群资源状态的维护者。其本身并不会通过 apiserver 修改任何的资源。其定义如下:
// GraphBuilder 处理 informers 提供的事件,更新 uidToNode,使用 LRU 缓存依赖资源,并将
// 资源送入到 attemptToDelete 和 attemptToOrphan 队列
type GraphBuilder struct {
restMapper meta.RESTMapper
// 每个 monitor 都会 list/watches 一个资源,结果会被导入到 dependencyGraphBuilder 中·
monitors monitors
monitorLock sync.RWMutex
informersStarted <-chan struct{}
stopCh <-chan struct{}
running bool
metadataClient metadata.Interface
// monitors 是该队列的生产者,graphBuilder 根据这些改变来修改内存中的 graph
graphChanges workqueue.RateLimitingInterface
// 资源 uid 对应到 graph 中的 node
uidToNode *concurrentUIDToNode
// GraphBuilder 是 attemptToDelete 和 attemptToOrphan 的生产者,GC 是消费者。
attemptToDelete workqueue.RateLimitingInterface
attemptToOrphan workqueue.RateLimitingInterface
// GraphBuilder 和 GC 共享 absentOwnerCache. 目前已知的不存在的对象会被添加到缓存中
absentOwnerCache *UIDCache
sharedInformers controller.InformerFactory
ignoredResources map[schema.GroupResource]struct{}
}
组成 graph 的 node 定义如下:
// 单线程的 GraphBuilder.processGraphChanges() 是 nodes 的唯一 writer。多线程的 GarbageCollector.attemptToDeleteItem() 读取 nodes。
type node struct {
identity objectReference
dependentsLock sync.RWMutex
// dependents 是当前 node 的依赖资源。比如当前 node 是 replicaset,那么这里面保存的应该就是多个 pod
dependents map[*node]struct{}
// this is set by processGraphChanges() if the object has non-nil DeletionTimestamp
// and has the FinalizerDeleteDependents.
deletingDependents bool
deletingDependentsLock sync.RWMutex
// this records if the object's deletionTimestamp is non-nil.
beingDeleted bool
beingDeletedLock sync.RWMutex
// this records if the object was constructed virtually and never observed via informer event
virtual bool
virtualLock sync.RWMutex
// when processing an Update event, we need to compare the updated
// ownerReferences with the owners recorded in the graph.
owners []metav1.OwnerReference
}
GraphBuilder 会和 apiserver 同步 monitors,然后为每种资源创建一个 monitor,通过 informer 同步资源的状态。所有的资源都会直接进入 graphChanges 队列。然后在 processGraphChanges 方法中统一处理。
对于 Add 和 Update 事件:
- 如果当前资源不存在 graph 中,就会实例化出一个 Node 对象,加入到 graph 中。然后将该 node 加入到其 owners 的 dependents 数组中。 这里有一个细节,就是有可能出现一种情况,当前 node 所代表的资源通过 informer 被同步到本地缓存中,但是其 owner 还没有被同步过来。这样更新 owners 的 dependents 就会有遗漏。因此每个 node 都有一个 virtual 字段,在 owner 还没有被同步时,实例化一个虚拟的 owner node 加入到 graph 中。并且将这个虚拟 node 添加到 attemptToDelete 队列中,由之后的 GC 处理。如果这个虚拟 node 在之后被 processGraphChanges 发现了,就会调用 markObserved() 将 virtual 置为 false。
- 如果已经存在了,那么就要比对新旧资源的 ownerReferences 的变化情况。这里会计算出 added, removed 和 changed。ownerReferences 的变化可能会带来以下要处理的情况。
- 之前提到 Foreground 的删除,ownerReference 带有 blockOwnerDeletion=true 的资源会 block 的 owner 的删除。那么这里因为 ownerReferences 的变化,需要做以下两点:
- 对于 removed 的 ownerReference,如果 blockOwnerDeletion 为 true。就说明当前不允许再 block 该 node owner 的删除。因此将 owner 放到 attemptToDelete 队列中,等待 GC 的处理。
- 对于更新的 ownerReference,如果之前 blockOwnerDeletion 为 true,现在为 false,那么也要加入到 attemptToDelete 队列。
- 对于 added 和 removed,都需要更新对应的 owner node 的 dependents。
- 无论是 Add 还是 Update 事件,都会调用
processTransitions方法,- 如果 old object 没有被删除或者没有 orphan finalizer,但是 new object 被删除了或者有 orphan finalizer,就会将该节点插入到 attemptToOrphan 队列。
- 如果 old object 没有被删除或者没有 foregroundDeletion finalizer,但是 new object 被删除了或者有 foregroundDeletion finalizer,就会将该节点的 dependents 都插入到 attemptToDelete 队列,再将节点插入到 attemptToDelete 队列。
对于删除事件:
- 会从当前的 graph 中移除该 node。起始就是从 uidToNode 中删除该 node,然后更新所有的 owner 的 dependents。
- 如果当前 node 的 dependents 大于 0,就将当前 node 添加到 absentOwnerCache 中。
- 将该 node 的 dependents 将入到 attemptToDelete 队列中(垃圾回收)。
- 最后,从该 node 中找到处于 deletingDependents=true 状态的 owner,也插入到 attemptToDelete 队列中。这里是为了让 GC 检查该 owner 是不是所有的 dependents 都被删除了,如果是,就将该 owner 也删除(这里 owner 处于 deletingDependents,说明使用了 foregroundDeletion,因此需要先删除 dependents,再删除 owner)。
因此可以知道,以下状态的资源会被插入到 attemptToDelete 队列中:
- finalizers 中有 foregroundDelete
- owner 的 finalizers 中有 foregroundDelete
- owner 资源被删除
- Dependents 中有资源被删除,并且当前状态还不是正在删除 deletingDependents
- owner 处于 deletingDependents
以下状态的资源会被插入到 attemptToOrphan 队列中:
- finalizers 中有 orphan
3.2 GarbageCollector 的实现
在 3.1 中提到,GC 会消费 GraphBuilder 的 attemptToDelete 和 attemptToOrphan 队列,来执行 delete 或 orphan 操作。因此我们这里主要关心,什么样的资源可以被 GC delete 或者 orphan。
3.2.1 attemptToDeleteItem
- 对于 DeletionTimestamp 不为空,并且不处于删除 dependents 的资源。直接跳过处理流程。
- 如果资源处于 deletingDependents 状态,则统计
blockOwnerDeletion=true的 dependents 个数。- 如果为 0,说明当前资源可以删除了,则移除 foregroundDeletion 这个 finalizer 即可。
- 否则将 dependents 插入到 attemptToDelete 队列中
- 之后会退出这个循环
- 对资源的 ownerReferences 进行分类
- Dangling: owner 对应的资源实际已经不存在了。
- waitingForDependentsDeletion: owner 的 DeletionTimeStamp 不为空,但是有 foregroundDeletion,所以正在等待 dependents 删除
- solid: owner 存在,并且不是 waitingForDependentsDeletion
- 如果 solid 不为空,那么当前资源就不能被 GC,因此只需要通过 patch 来移除 dangling 和 waitingForDependentsDeletion 的 ownerReferences
- 如果 waitingForDependentsDeletion 不为空并且当前资源的 dependents 不为空。这个判断用来处理循环依赖的异常情况,因为当前资源并不处于删除状态且有 dependents,其 owner 又在等待该 item 的删除,说明这里有一个循环依赖。解决办法就是通过 patch 去更改该资源的 blockOwnerDeletion 为 false。
- 如果上面两种情况都不是。就会根据当前资源的 finalizer 来删除资源
- orphan
- foreground
- Background
因此可以得出,以下状态的资源会被 GC 调用删除请求:
- 资源处于 deletingDependents 状态,且其没有 dependents 的 blockOwnerDeletion 为 true。先移除 foregroundDeletion finalizer,然后删除
- 资源的 owner 和 dependents 都有 blockOwnerDeletion。如果 dependents 处于 deletingDependents 状态。为了防止存在循环依赖,会先把 owner 的 unblock。然后使用 foreground 来删除当前资源。
- 资源没有 solid 的 owner,那么这个资源就是应该被级联删除的资源。所以根据该资源的 finalizer 来删除。默认使用 background 的方式删除。
3.2.2 attemptToOrphan
orphan 是防止某些情况下资源被 GC 回收的方式。attemptToOrphan 的逻辑要简短一些,如下:
- 移除 dependents 对当前资源 ownerReferences
- 移除该资源的 orphan finalizer (这个更新事件会被 GraphBuilder 获取到,然后该资源符合进入 attemptToDelete 队列的条件。之后再由 GC 的处理,最终会被删除。)
总结
根据以上流程,附上自己整理的一个整体的 GC 流程图