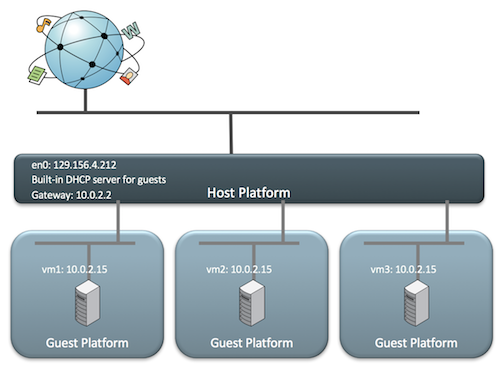
概述
在之前的一篇文章主要是分析了 gpu-manager 的启动流程。关于 gpu-manager 应该会有一系列的文章,一是觉得这是一个很有价值的项目,二是为这个项目花了好几天去看代码,想通过写文章的方式对内容进行梳理。
这篇文章主要分析 gpu-manager 的虚拟 gpu 分配原理,我认为将虚拟 gpu 分配给容器主要有两个重点:
- gpu-manager 作为 device plugin 的工作流程
- 虚拟 gpu 分配的最优方案,分配需要保证最少碎片,同时性能最好
从 pod 调度到虚拟 gpu 分配
这一部分会涉及到 device plugin 的工作机制,因此不熟悉的话可以看一下之前的一篇文章:Kubernetes开发知识–device-plugin的实现。下面附上一张这篇文章中 device plugin 的工作时序图:

在之前的启动流程分析文章中,说到 gpu-manager 向 kubelet 注册。在这之后, gpu-manager 就正式作为一个 device plugin 来工作了。这个时候,我们可以创建如下的 pod:
apiVersion: v1
kind: Pod
metadata:
name: tf-training-example-10
namespace: test
labels:
name: tf-training-example
spec:
restartPolicy: Never
containers:
- name: tf-training-example
image: joyme/tf_training_example:1.5
resources:
requests:
tencent.com/vcuda-core: 20
tencent.com/vcuda-memory: 15
limits:
tencent.com/vcuda-core: 20
tencent.com/vcuda-memory: 15
这个创建 pod 的请求会到达 kubernetes 的 API Server,然后由 kube-scheduler 进行调度。kube-scheduler 的调度经过预选和优选两个阶段,确定了最佳的目标节点。这时候 kubelet 就上场了。因为我们的 pod 中的容器请求了 vcuda-core 和 vcuda-memory 这两个资源,但是 kubelet 并没有能力去给容器分配这些资源,于是它就找是谁注册了这些资源类型,然后发现是 vcore 和 vmemory 这两个服务注册的,于是使用 grpc 和 /var/lib/kubelet/device-plugins/vcore.sock 以及 /var/lib/kubelet/device-plugins/vmemory.sock 通过 unix socket 通讯。
vcore 和 vmemory 是两种资源,因此这里其实相当于注册了两个 device plugin。
对于 vcuda-memory,kubelet 调用的 Allocate 方法如下:
/** device plugin interface */
func (vr *vmemoryResourceServer) Allocate(ctx context.Context, reqs *pluginapi.AllocateRequest) (*pluginapi.AllocateResponse, error) {
glog.V(2).Infof("%+v allocation request for vmemory", reqs)
fakeData := make([]*pluginapi.ContainerAllocateResponse, 0)
fakeData = append(fakeData, &pluginapi.ContainerAllocateResponse{})
return &pluginapi.AllocateResponse{
ContainerResponses: fakeData,
}, nil
}
这里其实并没有做任何实际分配操作,我们可以认为 vcuda-core 和 vcuda-memory 必然是同时申请分配的,因此我们只需要处理二者之一即可。
对于 vcuda-core,kubelet 会调用的 Allocate 方法代码如下:
func (vr *vcoreResourceServer) Allocate(ctx context.Context, reqs *pluginapi.AllocateRequest) (*pluginapi.AllocateResponse, error) {
glog.V(2).Infof("%+v allocation request for vcore", reqs)
return vr.mgr.Allocate(ctx, reqs)
}
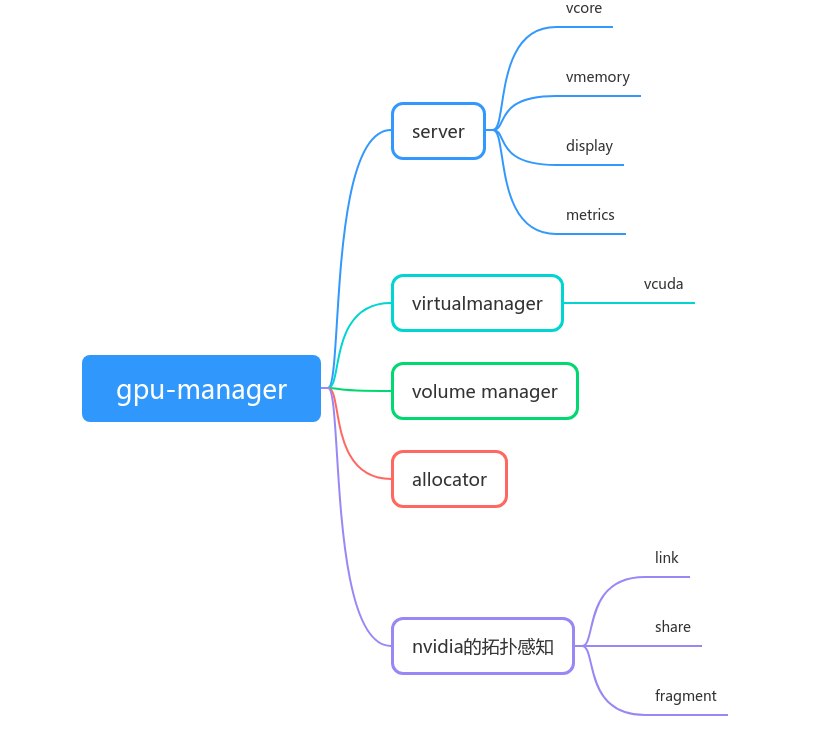
最终会走到 pkg/services/allocator/nvidia/allocator.go 的 Allcate 方法中。下面就来到这篇文章最复杂的部分了。
func (ta *NvidiaTopoAllocator) Allocate(_ context.Context, reqs *pluginapi.AllocateRequest) (*pluginapi.AllocateResponse, error) {
}
我们先看一下函数原型,reqs *pluginapi.AllocateRequest 这个参数是分配请求,然后返回了一个分配响应 *pluginapi.AllocateResponse。这里看一下 AllocateRequest:
// - Allocate is expected to be called during pod creation since allocation
// failures for any container would result in pod startup failure.
// - Allocate allows kubelet to exposes additional artifacts in a pod's
// environment as directed by the plugin.
// - Allocate allows Device Plugin to run device specific operations on
// the Devices requested
type AllocateRequest struct {
ContainerRequests []*ContainerAllocateRequest `protobuf:"bytes,1,rep,name=container_requests,json=containerRequests" json:"container_requests,omitempty"`
}
type ContainerAllocateRequest struct {
DevicesIDs []string `protobuf:"bytes,1,rep,name=devicesIDs" json:"devicesIDs,omitempty"`
}
很明显,请求里包含了每个容器需要的设备数组。同时通过 AllocateRequest 上的注释可以得出以下信息:
- Allocate 是在 pod 创建时被调用的,因此任何容器分配失败都会造成pod启动失败。
- Allocate 允许 kubelet 在 pod 环境中引入更多的 artifacts,这部分工作由我们的 device plugin 主导。对于 gpu manager 来说就是,覆盖容器内的 LD_LIBRARY_PATH,挂载 cuda 库文件等等。
- Allocate 允许 device plugin 在设备上运行特定的操作。
然后再来看一下 AllocateResponse:
// AllocateResponse includes the artifacts that needs to be injected into
// a container for accessing 'deviceIDs' that were mentioned as part of
// 'AllocateRequest'.
// Failure Handling:
// if Kubelet sends an allocation request for dev1 and dev2.
// Allocation on dev1 succeeds but allocation on dev2 fails.
// The Device plugin should send a ListAndWatch update and fail the
// Allocation request
type AllocateResponse struct {
ContainerResponses []*ContainerAllocateResponse `protobuf:"bytes,1,rep,name=container_responses,json=containerResponses" json:"container_responses,omitempty"`
}
type ContainerAllocateResponse struct {
// List of environment variable to be set in the container to access one of more devices.
Envs map[string]string `protobuf:"bytes,1,rep,name=envs" json:"envs,omitempty" protobuf_key:"bytes,1,opt,name=key,proto3" protobuf_val:"bytes,2,opt,name=value,proto3"`
// Mounts for the container.
Mounts []*Mount `protobuf:"bytes,2,rep,name=mounts" json:"mounts,omitempty"`
// Devices for the container.
Devices []*DeviceSpec `protobuf:"bytes,3,rep,name=devices" json:"devices,omitempty"`
// Container annotations to pass to the container runtime
Annotations map[string]string `protobuf:"bytes,4,rep,name=annotations" json:"annotations,omitempty" protobuf_key:"bytes,1,opt,name=key,proto3" protobuf_val:"bytes,2,opt,name=value,proto3"`
}
这里我们又可以看到一些关键信息,AllocateResponse 为每个容器返回了 ContainerAllocateResponse,包括容器的环境变量,容器的挂载,容器的设备信息,容器的 annotations 信息。其中,容器的设备信息如下:
// DeviceSpec specifies a host device to mount into a container.
type DeviceSpec struct {
// Path of the device within the container.
ContainerPath string `protobuf:"bytes,1,opt,name=container_path,json=containerPath,proto3" json:"container_path,omitempty"`
// Path of the device on the host.
HostPath string `protobuf:"bytes,2,opt,name=host_path,json=hostPath,proto3" json:"host_path,omitempty"`
// Cgroups permissions of the device, candidates are one or more of
// * r - allows container to read from the specified device.
// * w - allows container to write to the specified device.
// * m - allows container to create device files that do not yet exist.
Permissions string `protobuf:"bytes,3,opt,name=permissions,proto3" json:"permissions,omitempty"`
}
即在容器中挂载设备需要:
- 设备相对于容器的地址
- 设备在宿主机上的地址
- 设备的 Cgroups 信息
这时候我们再来重新思考 gpu-manager 的 gpu 虚拟化原理。如果你看过腾讯关于 Gaia Scheduler 的论文,就会知道 gpu-manager 需要做以下工作:
- 为容器挂载 cuda 相关的库,包括 vcuda-control 这个项目的拦截库
- 通过覆盖容器中的 LD_LIBRARY_PATH 来将 cuda 调用指向 libcuda-control.so 这个库,这个库里面对显存和计算 api 做了拦截。
- 为容器挂载 vcuda.sock,在容器调用特定的 cuda api 时,会触发 grpc 调用,通过 vcuda.sock 和 virtual manager 通信,virtual manager 下发容器配置。这样拦截库就知道自己应该怎么限制容器了。这里留一个问题 A,为什么要大费周章的通过 grpc,直接挂载容器配置文件可行吗?
这些 gpu-manager 要做的工作都是 device plugin 的 Allocate 调用提供的能力。所以 gpu-manager 需要在 Allocate 期间完成这么多的工作。这也是这部分比较复杂的原因。下面我们带着这些信息去看代码,会更容易懂一些。下面的代码都是来自于 pkg/services/allocator/nvidia/allocator.go 中的 Allocate 方法,但是因为很长,所以我会截取出来分析。
// k8s send allocate request for one container at a time
req := reqs.ContainerRequests[0]
resps := &pluginapi.AllocateResponse{}
reqCount = uint(len(req.DevicesIDs))
这部分取了 Allocate 中的第一个 ContainerRequest,通过注释知道,k8s 一次只为一个容器发送分配请求。
if ta.unfinishedPod != nil {
} else {
}
接下来有一个对 unfinishedPod 的判断,因为 k8s 一次请求只针对一个容器,因此这里的 unfinishedPod 指的是只分配了部分容器,还有其他容器没有分配的 pod。这里我们需要仔细思考一下,使用 unfinishedPod 的目的是什么?看到这里我有两个猜测:
- 因为 k8s 一次请求只针对一个容器,所以为了优先分配完一个 pod,就需要标记
unfinishedPod 了。但是仔细想想,因为 Allocate 的请求和响应中都没有容器的信息,所以本次请求分配的容器是由 kubelet 决定的。device plugin 并没有能力改变容器的分配顺序,这个想法是错的。
- 为了性能考虑。因为 gpu-manager 有两个 device plugin:vmemory 和 vcore。但是之前说到 vmemory 的分配没有做任何工作。所以我们不得不在分配 vcore 的时候,把 vmemory 的分配工作也做了。可是我怎么知道当前正在给哪个容器分配资源?那我也更不知道分配多少 vmemory 了。但是天无绝人之路啊,我可以遍历当前节点上的所有 pod,然后挑出需要 gpu 资源的 pod。然后再从这些 pod 中挑出符合这次请求的容器。这里如果使用
unfinishedPod 就避免了重复的大规模查找操作。
那么,假设现在还有一个未完成的 pod,会执行下面的代码
// 候选pod
candidatePod = ta.unfinishedPod
// 从已分配的pod中查找
cache := ta.allocatedPod.GetCache(string(candidatePod.UID))
if cache == nil {
msg := fmt.Sprintf("failed to find pod %s in cache", candidatePod.UID)
glog.Infof(msg)
return nil, fmt.Errorf(msg)
}
for i, c := range candidatePod.Spec.Containers {
if _, ok := cache[c.Name]; ok {
continue
}
if !utils.IsGPURequiredContainer(&c) {
continue
}
if reqCount != utils.GetGPUResourceOfContainer(&candidatePod.Spec.Containers[i], types.VCoreAnnotation) {
msg := fmt.Sprintf("allocation request mismatch for pod %s, reqs %v", candidatePod.UID, reqs)
glog.Infof(msg)
return nil, fmt.Errorf(msg)
}
// 候选的容器(应该就是待分配资源的容器)
candidateContainer = &candidatePod.Spec.Containers[i]
found = true
break
}
上面这段代码遍历这个 pod 的容器列表,然后和缓存中的容器对比,如果没有分配并且需要 gpu 资源,并且容器请求的资源量和当前的分配请求一致,就认定这个容器是我们接下来要为之分配的候选人了。这里我们又有一个问题 B,如果一个 Pod 中有多个 vcore 请求一致,但是 vmemory 不同的容器,这里只通过 vcore 的请求量来判断,可以保证这个分配请求和我们的候选容器能对的上吗?这个问题我们可以产生如下的猜测:
- AllocateRequest 是按照 Pod 中的容器顺序来的,这样我们在做 reqCount 对比的时候,因为顺序一致就能保证请求和候选容器是对应关系了。那么,AllocateRequest 是按照 Pod 中容器顺序来的吗?这是一个新的问题 C。
- 其实请求和候选容器不对应也没关系,因为容器中进行 cuda 调用拦截的时候,才会请求 virtual manager,拿到容器的资源限制配置信息。只要这个环节能保证容器和其请求的资源量对应上,就不会有任何问题?这也是我们的问题 E:cuda 调用拦截的时候,如何保证容器和配置的对应关系。这也和问题 A 相呼应,如果这个猜测成立,那就是为什么问题 A 中要大费周折的使用 grpc 调用下发配置,而不是直接把配置信息挂载或写到容器的变量中。
接下来我们继续看,如果没有未完成的容器,就执行以下代码:
// 获取候选的pod,候选的pod是当前节点上的需要GPU,没有分配并且不应该删除的pod
pods, err := getCandidatePods(ta.k8sClient, ta.config.Hostname)
if err != nil {
msg := fmt.Sprintf("Failed to find candidate pods due to %v", err)
glog.Infof(msg)
return nil, fmt.Errorf(msg)
}
for _, pod := range pods {
if found {
break
}
for i, c := range pod.Spec.Containers {
if !utils.IsGPURequiredContainer(&c) {
continue
}
podCache := ta.allocatedPod.GetCache(string(pod.UID))
if podCache != nil {
if _, ok := podCache[c.Name]; ok {
glog.Infof("container %s of pod %s has been allocate, continue to next", c.Name, pod.UID)
continue
}
}
if utils.GetGPUResourceOfContainer(&pod.Spec.Containers[i], types.VCoreAnnotation) == reqCount {
glog.Infof("Found candidate Pod %s(%s) with device count %d", pod.UID, c.Name, reqCount)
candidatePod = pod
candidateContainer = &pod.Spec.Containers[i]
found = true
break
}
}
}
和上面的不同之处,就是在获取候选 pod 这里。获取候选 pod 的代码如下:
candidatePods := []*v1.Pod{}
allPods, err := getPodsOnNode(client, hostname, string(v1.PodPending))
for _, pod := range allPods {
current := pod
if utils.IsGPURequiredPod(¤t) && !utils.IsGPUAssignedPod(¤t) && !utils.ShouldDelete(¤t) {
candidatePods = append(candidatePods, ¤t)
}
}
return OrderPodsdByPredicateTime(candidatePods), nil
先是获取节点上的所有 pod,然后从节点上的 pod 中选取需要 GPU,并且没有分配 GPU,并且不应该删除的 pod。最后得到一个候选 pod 列表。最后对这个列表根据时间排序。这样就可以拿到最先被调度的 pod 了。这里其实也默认了一个前提,最先调度的 pod 会最先发出分配请求。这里还有一个需要注意的地方,排序依据的时间有两个选择:预选时间或创建时间。
if predicateTimeStr, ok := pod.ObjectMeta.Annotations[types.PredicateTimeAnnotation]; ok {
u64, err := strconv.ParseUint(predicateTimeStr, 10, 64)
if err != nil {
glog.Warningf("Failed to parse predicate Timestamp %s due to %v", predicateTimeStr, err)
} else {
predicateTime = u64
}
} else {
// If predicate time not found, use createionTimestamp instead
predicateTime = uint64(pod.ObjectMeta.CreationTimestamp.UnixNano())
}
return predicateTime
其中,预选时间并不是 kube-scheduler 添加的,而是和 gpu-manager 配合使用的 gpu-admission 这个项目。如果没有预选时间,就会使用 pod 的创建时间。这也就是说,我们不使用 gpu-admission 这个项目,也可以正常使用 gpu-manager。其实这里还有一个问题 D,我怎么保证挑出来的容器就是这次分配请求的呢?这个问题还要留在后面的分析中。
现在我们拿到了候选容器,就需要进行真正的分配工作了。
// get vmemory info from container spec
vmemory := utils.GetGPUResourceOfContainer(candidateContainer, types.VMemoryAnnotation)
for i := 0; i < int(vmemory); i++ {
req.DevicesIDs = append(req.DevicesIDs, types.VMemoryAnnotation)
}
resp, err := ta.allocateOne(candidatePod, candidateContainer, req)
if err != nil {
glog.Errorf(err.Error())
return nil, err
}
resps.ContainerResponses = append(resps.ContainerResponses, resp)
这段代码中,我们拿到容器的 vmemory 信息。因为 vmemory 是根据数量划分的。1 个 vmemory 相当于 256M 的 memory,也就是一个 deviceID。这里请求多少的 vmemory,就存多少个 deviceID。然后调用 allocateOne 为单个容器进行真正的分配工作。下面我们开始分析 allocateOne 的分配逻辑。
var (
nodes []*nvtree.NvidiaNode
needCores, needMemoryBlocks int64
predicateMissed bool
allocated bool
)
// 是否是 gpu 预选 pod
predicateMissed = !utils.IsGPUPredicatedPod(pod)
// 单节点的总内存
singleNodeMemory := int64(ta.tree.Leaves()[0].Meta.TotalMemory)
for _, v := range req.DevicesIDs {
if strings.HasPrefix(v, types.VCoreAnnotation) {
// 请求 core
needCores++
} else if strings.HasPrefix(v, types.VMemoryAnnotation) {
// 请求 memory
needMemoryBlocks++
}
}
首先就是根据 deviceID 来计算需要多少 core 和 memory。接下来会调用 ta.recycle() 回收资源。回收的逻辑如下:
func (ta *NvidiaTopoAllocator) recycle() {
activePods := watchdog.GetActivePods()
lastActivePodUids := sets.NewString()
activePodUids := sets.NewString()
for _, uid := range ta.allocatedPod.Pods() {
lastActivePodUids.Insert(uid)
}
for uid := range activePods {
activePodUids.Insert(uid)
}
// difference 出来的就是已经运行结束的pod,可以回收分配的gpu资源
podsToBeRemoved := lastActivePodUids.Difference(activePodUids)
glog.V(5).Infof("Pods to be removed: %v", podsToBeRemoved.List())
// 释放资源
ta.freeGPU(podsToBeRemoved.List())
}
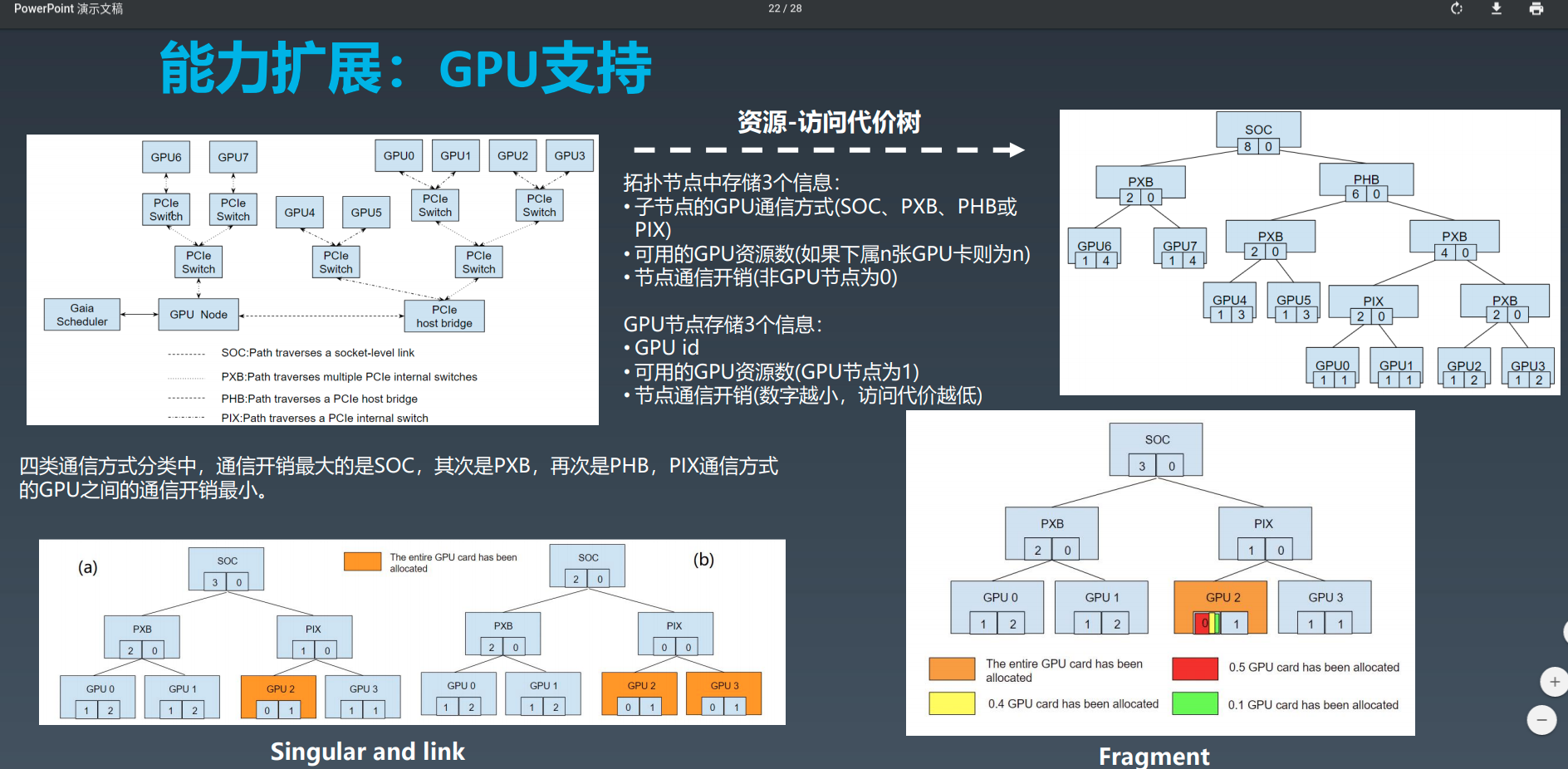
对已分配的 pod 和 正在运行的 pod 集合取差集,差集就是分配了资源但是已经停止运行的 pod 。然后对这部分 pod 释放 GPU 资源。具体的释放逻辑放在后面分析。现在继续向下看,这里我们直接跳到尝试分配资源的逻辑上。分配 gpu 资源分为三种情况:
- 如果需要的核心数大于 100,也就是说超过一个物理 GPU,就使用 link 评估器来选出 GPU 节点
- 如果正好是一个 100 核心,则使用 fragment 评估器
- 如果小于 100 核心,则使用 share 评估器。
情况 1 的代码如下:
eval, ok := ta.evaluators["link"]
if !ok {
return nil, fmt.Errorf("can not find evaluator link")
}
if needCores%nvtree.HundredCore > 0 {
return nil, fmt.Errorf("cores are greater than %d, must be multiple of %d", nvtree.HundredCore, nvtree.HundredCore)
}
nodes = eval.Evaluate(needCores, 0)
注意到这里还要求请求的核心数必须是 100 的整数,也就是说必须是整数个物理 GPU,你不能请求 1.5 个 物理 GPU 这种。
情况 2 的代码如下:
eval, ok := ta.evaluators["fragment"]
if !ok {
return nil, fmt.Errorf("can not find evaluator fragment")
}
nodes = eval.Evaluate(needCores, 0)
情况 3 的代码如下:
// EnableShare 是在启动时指定的参数,代表是否允许多个容器共享一个gpu
if !ta.config.EnableShare {
return nil, fmt.Errorf("share mode is not enabled")
}
if needCores == 0 || needMemory == 0 {
return nil, fmt.Errorf("that cores or memory is zero is not permitted in share mode")
}
// evaluate in share mode
shareMode = true
// 使用 share 评估
eval, ok := ta.evaluators["share"]
if !ok {
return nil, fmt.Errorf("can not find evaluator share")
}
// 评估出来的合适的 nvidia gpu 节点
nodes = eval.Evaluate(needCores, needMemory)
if len(nodes) == 0 {
if shareMode && needMemory > singleNodeMemory {
return nil, fmt.Errorf("request memory %d is larger than %d", needMemory, singleNodeMemory)
}
return nil, fmt.Errorf("no free node")
}
在评估出来节点之后,会先判断这个这个 pod 是否真的经过预选阶段?判断方法如下:
func IsGPUPredicatedPod(pod *v1.Pod) (predicated bool) {
glog.V(4).Infof("Determine if the pod %s needs GPU resource", pod.Name)
var ok bool
// Check if pod request for GPU resource
if GetGPUResourceOfPod(pod, types.VCoreAnnotation) <= 0 || GetGPUResourceOfPod(pod, types.VMemoryAnnotation) <= 0 {
glog.V(4).Infof("Pod %s in namespace %s does not Request for GPU resource",
pod.Name,
pod.Namespace)
return predicated
}
// Check if pod already has predicate time
// tencent.com/predicate-time 是 gpu-admission 中添加的。
if _, ok = pod.ObjectMeta.Annotations[types.PredicateTimeAnnotation]; !ok {
glog.V(4).Infof("No predicate time for pod %s in namespace %s",
pod.Name,
pod.Namespace)
return predicated
}
// Check if pod has already been assigned
if assigned, ok := pod.ObjectMeta.Annotations[types.GPUAssigned]; !ok {
glog.V(4).Infof("No assigned flag for pod %s in namespace %s",
pod.Name,
pod.Namespace)
return predicated
} else if assigned == "true" {
glog.V(4).Infof("pod %s in namespace %s has already been assigned",
pod.Name,
pod.Namespace)
return predicated
}
predicated = true
return predicated
}
共有三个要求才算经过了预选:
- resource 字段请求了 vcore 和 vgpu,并且大于 0。
- 必须有
tencent.com/predicate-time 字段。这点要求必须经过 gpu-admission 的预选阶段。
- 没有被分配 gpu 资源
如果经过预选的话,就需要执行以下的逻辑:
// get predicate node by annotation
containerIndex, err := utils.GetContainerIndexByName(pod, container.Name)
if err != nil {
return nil, err
}
var devStr string
if idxStr, ok := pod.ObjectMeta.Annotations[types.PredicateGPUIndexPrefix+strconv.Itoa(containerIndex)]; ok {
if _, err := strconv.Atoi(idxStr); err != nil {
return nil, fmt.Errorf("predicate idx %s invalid for pod %s ", idxStr, pod.UID)
}
devStr = types.NvidiaDevicePrefix + idxStr
if !utils.IsValidGPUPath(devStr) {
return nil, fmt.Errorf("predicate idx %s invalid", devStr)
}
} else {
return nil, fmt.Errorf("failed to find predicate idx for pod %s", pod.UID)
}
predicateNode := ta.tree.Query(devStr)
if predicateNode == nil {
return nil, fmt.Errorf("failed to get predicate node %s", devStr)
}
// check if we choose the same node as scheduler
if predicateNode.MinorName() != nodes[0].MinorName() {
return nil, fmt.Errorf("Nvidia node mismatch for pod %s(%s), pick up:%s predicate: %s",
pod.Name, container.Name, nodes[0].MinorName(), predicateNode.MinorName())
}
也就是说,经过预选阶段的 Pod 都会根据容器的顺序在 Annotations 为该容器写上配置信息。这说明在 gpu-admission 这个项目中会为容器分配 gpu 设备。最后还要检查一下在 gpu-manager 中分配的 gpu 设备和 gpu-admission 中是否一致,不一致的话也会返回分配失败。
现在我们已经知道要为当前请求的容器分配哪个 gpu 设备,以及分配的资源数量。这样就可以构建 ContainerAllocateResponse 了。先把已分配的设备放到响应中:
for _, n := range nodes {
name := n.MinorName()
glog.V(2).Infof("Allocate %s for %s(%s), Meta (%d:%d)", name, pod.UID, container.Name, n.Meta.ID, n.Meta.MinorID)
ctntResp.Annotations[types.VCoreAnnotation] = fmt.Sprintf("%d", needCores)
ctntResp.Annotations[types.VMemoryAnnotation] = fmt.Sprintf("%d", needMemory)
ctntResp.Devices = append(ctntResp.Devices, &pluginapi.DeviceSpec{
ContainerPath: name,
HostPath: name,
Permissions: "rwm",
})
deviceList = append(deviceList, n.Meta.UUID)
if !allocated {
// 在 gpu tree 中标记设备已占用
ta.tree.MarkOccupied(n, needCores, needMemory)
}
allocatedDevices.Insert(name)
}
更改响应的 Annotations:
ctntResp.Annotations[types.VDeviceAnnotation] = vDeviceAnnotationStr(nodes)
检查 pod 的所有容器是否都完成了分配,并把新的分配信息写入到 checkpoint:
unfinished := false
for _, c := range pod.Spec.Containers {
if !utils.IsGPURequiredContainer(&c) {
continue
}
podCache := ta.allocatedPod.GetCache(string(pod.UID))
if podCache != nil {
if _, ok := podCache[c.Name]; !ok {
unfinished = true
break
}
}
}
if unfinished {
ta.unfinishedPod = pod
} else {
ta.unfinishedPod = nil
}
ta.writeCheckpoint()
在响应中为容器添加 /dev/nvidiactl 和 /dev/nvidia-uvm,如果配置了 extraConfig,还会把里面要默认添加的设备加进去:
// Append control device
ctntResp.Devices = append(ctntResp.Devices, &pluginapi.DeviceSpec{
ContainerPath: types.NvidiaCtlDevice,
HostPath: types.NvidiaCtlDevice,
Permissions: "rwm",
})
ctntResp.Devices = append(ctntResp.Devices, &pluginapi.DeviceSpec{
ContainerPath: types.NvidiaUVMDevice,
HostPath: types.NvidiaUVMDevice,
Permissions: "rwm",
})
// Append default device
if cfg, found := ta.extraConfig["default"]; found {
for _, dev := range cfg.Devices {
ctntResp.Devices = append(ctntResp.Devices, &pluginapi.DeviceSpec{
ContainerPath: dev,
HostPath: dev,
Permissions: "rwm",
})
}
}
此时,响应中的设备信息已经处理结束,接下来处理容器中的环境变量,gpu manager 需要通过修改 LD_LIBRARY_PATH 来劫持程序对 cuda 的调用,然后通过 NVIDIA_VISIBLE_DEVICES 来让挂载的设备可见。
// LD_LIBRARY_PATH
ctntResp.Envs["LD_LIBRARY_PATH"] = "/usr/local/nvidia/lib64"
for _, env := range container.Env {
if env.Name == "compat32" && strings.ToLower(env.Value) == "true" {
ctntResp.Envs["LD_LIBRARY_PATH"] = "/usr/local/nvidia/lib"
}
}
// NVIDIA_VISIBLE_DEVICES
ctntResp.Envs["NVIDIA_VISIBLE_DEVICES"] = strings.Join(deviceList, ",")
接着根据是否处于 shareMode,也就是单个 gpu 能否被共享来挂载不同的 host 目录。
if shareMode {
// nvidia 是劫持的库,用在shareMode这种情况
ctntResp.Mounts = append(ctntResp.Mounts, &pluginapi.Mount{
ContainerPath: "/usr/local/nvidia",
HostPath: types.DriverLibraryPath,
ReadOnly: true,
})
} else {
// 非shareMode用正常的库即可
ctntResp.Mounts = append(ctntResp.Mounts, &pluginapi.Mount{
ContainerPath: "/usr/local/nvidia",
HostPath: types.DriverOriginLibraryPath,
ReadOnly: true,
})
}
shareMode 下,会挂载的 host 目录是 /etc/gpu-manager/vdriver/nvidia,这里面是被劫持的库。否则挂载 /etc/gpu-manager/vdriver/origin,里面是原始的 CUDA 库。
紧接着,将 host 上的 /etc/gpu-manager/vm/{podUID} 挂载到容器中,这个是为了容器内可以通过 vcuda.sock 和 virtual-manager 通信。
// 将host上的/etc/gpu-manager/vm/podUID挂载进去(vcuda.sock),这个目录是在PreStartContainer期间由VirtualManager创建的
ctntResp.Mounts = append(ctntResp.Mounts, &pluginapi.Mount{
ContainerPath: types.VCUDA_MOUNTPOINT,
HostPath: filepath.Join(ta.config.VirtualManagerPath, string(pod.UID)),
ReadOnly: true,
})
如果当前请求的容器所属 Pod 没有经过 gpu-admission,还会被放到一个处理队列中:
if predicateMissed {
ar := &allocateResult{
pod: pod,
result: PREDICATE_MISSING,
resChan: make(chan struct{}),
}
// 这个 queue 的处理是在virtualmanager里面的process方法
ta.queue.AddRateLimited(ar)
<-ar.resChan
}
这个队列会在 pkg/service/allocator/nvidia/allocator.go 的 proccessResult 中处理。
这样,kubelet 调用 Allocate 方法就结束了。这里再来回顾一下上面遗留的问题和相关逻辑:
问题:
- 问题 A: 为什么要大费周章的通过 grpc,直接挂载容器配置文件可行吗?
总结: 这一点在上面的阅读中可以发现,这时候容器本身对自己应该限制多少的 gpu 资源调用并不知道。这个问题得和 B/C/D 问题结合来看。因为做 Allocate 调用时,kubelet 并没有告知此时在为哪个容器请求配置。因此只能根据请求的资源量以及 Pod 的 predicateTime 或 createTime 来判断。这个是无法保证一定准确的,因此此时容器的具体资源配置也无法确定。可能这就是要通过 grpc 而不是挂载容器配置文件的原因吧。
-
问题 B: 如果一个 Pod 中有多个 vcore 请求一致,但是 vmemory 不同的容器,这里只通过 vcore 的请求量来判断,可以保证这个分配请求和我们的候选容器能对的上吗?
总结:问题 B 是在 unfinisedPod 中查找当前请求的容器。只要能保证 unfinishedPod 是正确的(问题 D 说明不能保证),那么就可以保证容器是对的上的(问题 C 保证了这个结论)。
-
问题 C: AllocateRequest 是按照 Pod 中的容器顺序来的?
总结:对于这个问题,最好的回答方式是去看 kubelet 的源代码。
for _, container := range pod.Spec.Containers {
if err := m.allocateContainerResources(pod, &container, devicesToReuse); err != nil {
return err
}
m.podDevices.removeContainerAllocatedResources(string(pod.UID), container.Name, devicesToReuse)
}
这边做 Allocate 的时候,是顺序遍历 Pod 中的容器,因此这个问题的答案是肯定的。
-
问题 D: 遍历当前节点上的所有 pod,然后挑出需要 gpu 资源的 pod,根据 predicatedTime 或 createTime 排序。然后再从这些 pod 中, 按顺序挑出符合这次请求的容器,怎么保证挑出来的容器就是这次分配请求的呢?
总结:我觉得回答这个问题,需要确定两个大前提,一是 Pod 从创建到发起 Allocate 的过程,都是顺序的。这样就能保证当调用 Allocate 对应的 Pod 永远是尚未分配到资源的第一个。二是在一个 Pod 中,为每个容器 Allocate 时,也是顺序的,这一点在问题 C 中得到确认。
但是实际上,第一个前提是不能保证的,在 Pod bind 到节点时,这个是并发执行的。因此可以得出一个结论:在这个阶段无法保证 Allocate 请求和我们的候选容器是对应关系。关于这一点我也提了个 issue:a question about Allocate for a container?。官方也给了回答,因为这个原因 gpu manager 有时候会报 UnexpectedAdmissionError 错误。
所以根据问题 4,我们还要使用 gpu-admission 这个项目,来保证该阶段的正确性,具体机制还得等到看 gpu-admission 的时候才能知道了。
其实以上四个问题都是因为 kubelet 的 Allocate 请求不会带上正在分配的容器。所以需要一系列的查找方式来确定具体的容器。
因为篇幅问题,关于 gpu 的最佳分配策略会作为下一篇文章的内容。
参考资料
从零开始入门 K8s:调度器的调度流程和算法介绍