一、前言
缓存在整个计算机体系中,占据着举足轻重的地位,往往被用于提升软件的运行速度。在计算机系统中,最典型的当属CPU高速缓存了,CPU高速缓存是介于CPU寄存器和内存之间,CPU向内存中请求数据时,会先检查CPU高速缓存中是否存在数据,如果不存在,则会将内存中的数据放入高速缓存中,再将高速缓存中的数据读入CPU。这个过程中,缓存之所以能够大大的提升系统速度,是因为程序在运行的时候对内存的访问具有局部性的特点,这种局部性我理解为程序在运行时对某一块的内存请求会非常频繁,而这一块内存在第一次请求之后就会被缓存,所以会大大提升之后的数据读取速度。所以,缓存设计的是否合理有效,在于缓存的命中率高不高。
在leveldb中,为了提升对数据的检索速度,也设计了缓存,对应的代码在db/table_cache.h和db/table_cache.cc中,这个table cache的实现主要借助于Cache类,关于Cache类,是可以用户自定义实现的,但leveldb也有一个内置的Cache的实现,文件是util/cache.cc。主要是LRU(最近最少使用)算法,原理是“如果一个数据最近被使用,那么将来被使用的概率同样也很大”。同样也实现了一个HashTable,leveldb中提供的数据显示在g++ 4.4.3下比built-in的哈希表性能稍高,大概5%左右。
二、概览
2.1 hash table数据结构
哈希表是一个很常见的结构了,存储的是key-value结构,一个key-value对常被称作entry,它最大的特点是查找快。在网上找了一张hash table的图
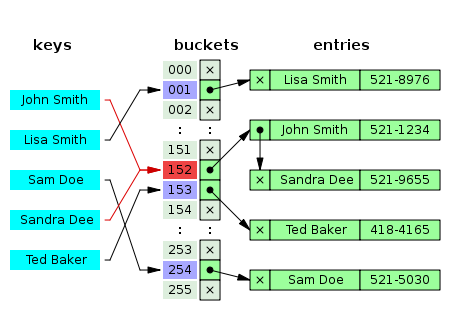
首先它是一个长为len的数组,每个数组中的元素都是一个链表。如图所示,john Smith和Sandra Dee都被hash到152这个地方,所以在152这个地方使用链表来存储这两个entry.查找的时候Sandra Dee的时候,先找到152这个地方,在遍历链表,直到找到key是Sandra的entry。
2.2 LRU算法
在leveldb中,LRU算法的实现是使用两个双向环形链表,一个链表(in-use)存储当前正在使用的数据,另一个链表(lru)按照访问时间先后顺序存储缓存数据,每个数据都可以在in-use和lru之间切换。当我们需要使用LRU算法来淘汰数据时,只需要在lru上淘汰排序靠后的数据即可。
2.3 分片LRU缓存
分片LRU缓存很简单,其实就是同时创建多个LRU缓存对象,然后使用hash将特定的缓存数据放置到相应的LRU缓存对象中。这个方式可以避免一个LRU缓存中存储过多的数据。
三、详细分析
3.1 Hash Table
leveldb中实现了HashTable,使用的是最经典的数组+链表的实现。通过hash值定位到数组中的某一处,然后在这一处的链表上遍历查找。
HashTable的长度是哈希算法效率的最大影响因素,如果存在较多的hash冲突,则在链表上遍历查找的时间花费会很长。所以这个长度的选择是很重要的,比如在Java中的HashMap,实现中有一个负载因子0.7,如果数组上已经有值的数量超过总长度的0.7就会对整个哈希表resize。在leveldb中,这个resize的阈值是当前所有Insert进来的元素个数超过了数组的长度length,就会进行resize。这里简单的分析一下最重要的查找和resize过程。
- 哈希表查找过程
// Return a pointer to slot that points to a cache entry that
// matches key/hash. If there is no such cache entry, return a
// pointer to the trailing slot in the corresponding linked list.
LRUHandle** FindPointer(const Slice& key, uint32_t hash) {
LRUHandle** ptr = &list_[hash & (length_ - 1)]; //这里hash & (length_ - 1)会定位到小于length的位置,ptr就是hash到的位置
while (*ptr != NULL &&
((*ptr)->hash != hash || key != (*ptr)->key())) {
//hash到特定位置后,如果当前位置的hash和当前hash不一样,或者key不一样,并且指针也不为空,则继续向下找,直到找到
ptr = &(*ptr)->next_hash;
}
return ptr;
}
- 哈希表resize的过程
void Resize() {
uint32_t new_length = 4; //哈希表的长度从4开始,逐倍增长
while (new_length < elems_) {
new_length *= 2;
}
LRUHandle** new_list = new LRUHandle*[new_length];
memset(new_list, 0, sizeof(new_list[0]) * new_length); //申请新的哈希表的所需的空间
uint32_t count = 0;
for (uint32_t i = 0; i < length_; i++) { //将旧的哈希表的数据重新计算复制到新的哈希表中
LRUHandle* h = list_[i];
while (h != NULL) {
LRUHandle* next = h->next_hash;
uint32_t hash = h->hash;
LRUHandle** ptr = &new_list[hash & (new_length - 1)];
h->next_hash = *ptr;
*ptr = h;
h = next;
count++;
}
}
assert(elems_ == count);
delete[] list_; //删除旧的哈希表
list_ = new_list;
length_ = new_length;
}
};
3.2 LRUCache的实现
这里的LRUCache的私有成员变量包括以下几个
// Initialized before use.
size_t capacity_; //LRUCache的大小。
// mutex_ protects the following state.
mutable port::Mutex mutex_; //互斥变量,用来同步访问
size_t usage_; //LRUCache已经使用的大小
// Dummy head of LRU list.
// lru.prev is newest entry, lru.next is oldest entry.
// Entries have refs==1 and in_cache==true.
LRUHandle lru_; //LRU链表的头,lru.prev代表新的节点,lru.next代表旧的节点,节点的refs == 1,in_cache == true
// Dummy head of in-use list.
// Entries are in use by clients, and have refs >= 2 and in_cache==true.
LRUHandle in_use_; //正在使用的节点链表的头,refs >= 2,in_cache == true
HandleTable table_; //哈希表,用来在缓存中实现快速查找
LRU的构造函数,直接构造出空的环形链表
LRUCache::LRUCache()
: usage_(0) {
// Make empty circular linked lists.
lru_.next = &lru_;
lru_.prev = &lru_;
in_use_.next = &in_use_;
in_use_.prev = &in_use_;
}
LRU中节点的引用和解引用
//增加引用时,如果在缓存中,则移动到in_use中
void LRUCache::Ref(LRUHandle* e) {
if (e->refs == 1 && e->in_cache) { // If on lru_ list, move to in_use_ list.
LRU_Remove(e);
LRU_Append(&in_use_, e);
}
e->refs++;
}
//解引用时会出现两种情况。1.节点不再需要,使用deleter来删除节点 2.不再被使用,移动到缓存
void LRUCache::Unref(LRUHandle* e) {
assert(e->refs > 0);
e->refs--;
if (e->refs == 0) { // Deallocate.
assert(!e->in_cache);
(*e->deleter)(e->key(), e->value);
free(e);
} else if (e->in_cache && e->refs == 1) { // No longer in use; move to lru_ list.
LRU_Remove(e);
LRU_Append(&lru_, e);
}
}
缓存的插入
Cache::Handle* LRUCache::Insert(
const Slice& key, uint32_t hash, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value)) {
MutexLock l(&mutex_);
LRUHandle* e = reinterpret_cast<LRUHandle*>(
malloc(sizeof(LRUHandle)-1 + key.size())); //这个地方申请内存需要注意,在LRUHandle中,key_data只有1个字节,其实是整个key的开头一个字节,所以申请的空间实际上是包含整个key的
e->value = value;
e->deleter = deleter;
e->charge = charge;
e->key_length = key.size();
e->hash = hash;
e->in_cache = false;
e->refs = 1; // for the returned handle.
memcpy(e->key_data, key.data(), key.size());
if (capacity_ > 0) { //如果capacity大于0,也就是需要进行缓存
e->refs++; // for the cache's reference.
e->in_cache = true;
LRU_Append(&in_use_, e);
usage_ += charge;
FinishErase(table_.Insert(e));
} // else don't cache. (Tests use capacity_==0 to turn off caching.)
//当使用的内存大于容量时,则要移除旧的缓存,直到缓存小于指定的容量
while (usage_ > capacity_ && lru_.next != &lru_) {
LRUHandle* old = lru_.next;
assert(old->refs == 1);
bool erased = FinishErase(table_.Remove(old->key(), old->hash));
if (!erased) { // to avoid unused variable when compiled NDEBUG
assert(erased);
}
}
return reinterpret_cast<Cache::Handle*>(e);
}
缓存的查找
Cache::Handle* LRUCache::Lookup(const Slice& key, uint32_t hash) {
MutexLock l(&mutex_);
LRUHandle* e = table_.Lookup(key, hash); //直接借用哈希表完成缓存的快速查找
if (e != NULL) {
Ref(e);
}
return reinterpret_cast<Cache::Handle*>(e);
}
3.3 分片缓存的实现(ShardedLRUCache)
分片缓存的实现其实就是借助上面的LRUCaChe,只不过同时拥有多个LRUCache,然后特定的缓存数据会被缓存到相应的LRUCache中。
static const int kNumShardBits = 4; //可以理解为缓存片数量的容量因子(这里是4个bits,所以共有16个缓存片)
static const int kNumShards = 1 << kNumShardBits; //一共有多少个缓存片
//通过Shard函数可以将任意一个hash分配到16个缓存片中的任意一个)
static uint32_t Shard(uint32_t hash) {
return hash >> (32 - kNumShardBits);
}
所有的缓存存储和读取都会通过上面的Shard函数来找到特定的缓存片,从而实现了分片缓存。
五、总结
在这个部分,400行左右的代码就实现了哈希表,LRU缓存,分片LRU缓存。了解到LRU缓存的具体实现方式,特别是LRU中Ref和UnRef的实现非常精炼,很好的解决了一个数据在LRU缓存中被引用时脱离缓存,不使用时进入LRU缓存的功能。同时将LRU缓存简单的封装,就可以实现分片LRU缓存。
