问题背景
客户的机房部署了多套不同架构的 k8s 集群:Intel CPU + redhat OS,海光 CPU + 麒麟 OS。其中 Intel CPU + redhat OS 的 k8s 已经稳定运行了很久。海光 CPU + 麒麟 OS 是后来上线的,主要是为了满足信创的要求。但是在实际使用中发现,海光 CPU + 麒麟 OS 的 k8s 集群中,运行的服务在压测时会偶现服务请求 redis 超时的异常。
问题定位
因为同样的服务,在非信创的机器上可以正常运行,因此排除服务本身的问题。主要排查硬件+操作系统+ k8s CNI 这几个环节。这里之所以要排查 CNI 的问题,主要还是考虑这个 CNI 是专门为这个客户开发的,用来实现 Underlay 的网络,以及一系列的特殊网络需求。
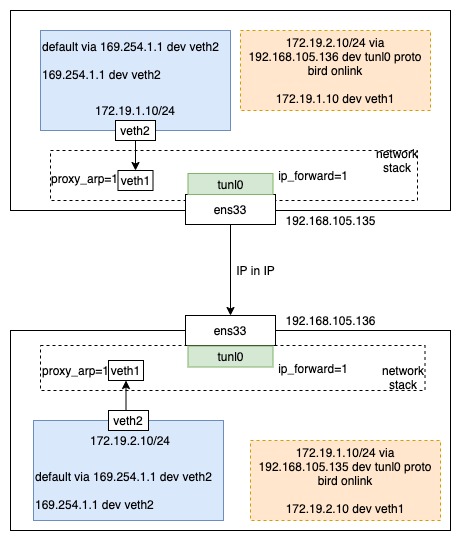
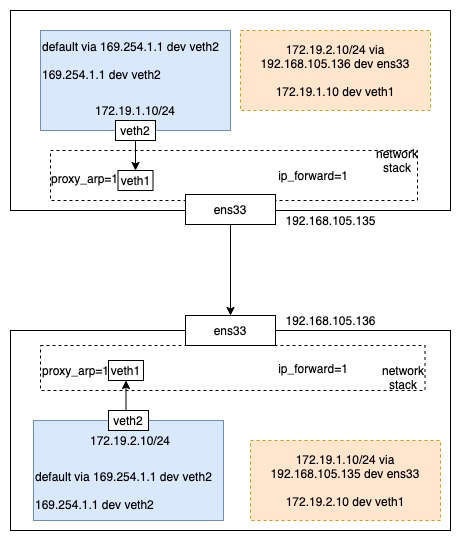
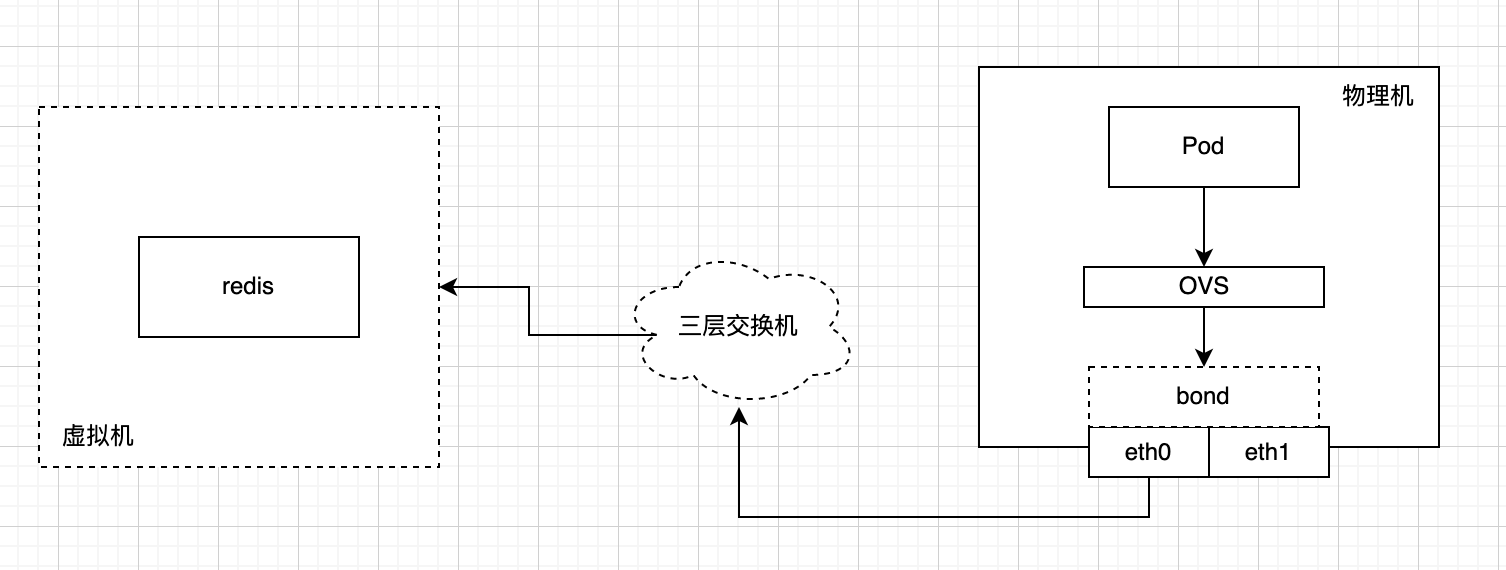
整个网络的链路如图所示:
抓包分析
首先是在 Pod 内用 tcpdump 进行长时间的抓包,保存的本地文件。然后进行压测来复现问题。根据日志找到出问题的时间点,用 wireshark 自带的命令对抓包文件按时间切割。
# 每 10s 保存一个分片。
editcap -i 10 tcpdump.cap pod1111
用 wireshark 打开对应时间片段的抓包文件进行分析。这里因为安全要求不方便放上异常包的截图。大概描述一下问题现象:分析的是 tcp 包,表现为异常时间点 redis 回包存在大量重传,且重传的包几乎都在同一时刻到达 Pod 内。
因此下一步要排查 tcp 包的延迟发生链路上的什么位置。因此选择同时在 redis 虚拟机,物理机网卡 eth0,pod 内网卡抓包。然后用同样的方式进行问题复现。
因为有了多个位置点的抓包数据,根据 tcp 的 seq 号就可以分析同一个数据包从 redis 虚拟机发出来的时间,以及到达物理机 eth0 以及 Pod 内的时间。然后根据时间就可以找到延迟点在哪。
分析后发现延迟在 redis→物理机这条链路上。redis 出来的包因为延迟到达了物理机,因此也延迟到达 Pod 内。redis 所在的虚拟机发包后因为一直没有收到回报,因此会触发 tcp 的重传机制。但是重传的包也出现了延迟。最终原始包和重传包在某一刻同时进入了物理机。
因此怀疑是交换机上出现了延迟,但是如果是交换机的问题,那么接入该交换机的其他机器也一定会出问题才对。但是现象仅局限于信创服务器上。所以也和麒麟的供应商沟通了,他们怀疑是一个已知的 cgroup 问题导致的,出现在 4.19 前的内核里。升级内核后果然问题就解决了。
问题分析
上面说的 cgroup 问题,详细来说是 kubelet 中的 cadvisor 在采集 node 的内存信息时,会读取 /sys/fs/cgroup/memory/memory.numa_stat 信息。但是因为内核的实现会导致这个读取信息的系统调用很慢。慢的原因有两点:
- cgroup 是通过 cgroup 伪文件系统来管理的,可以通过删除伪文件系统中的文件目录来删除相应的 cgroup。但是内核中代表 cgroup 的结构体会仍然存在,直到所有对它的引用被释放。只有当被删除的 memory cgroup 中的页都被回收掉,相应的引用都被释放,该 memory cgroup 才会被彻底删除。系统中所有的 memory cgroup 数量可以通过
cat /proc/cgroups来查看。而内存页的回收时间与内核的回收机制有关,如果当中有一些页一直活跃的被使用,就可能永远不会被回收。 - cadvisor 读取 /sys/fs/cgroup/memory/memory.numa_stat 信息时,其实是一个系统调用。这个调用的实现也存在性能问题,它会遍历所有的子 cgroup 层级,累加 memory 的使用信息求和,得到总的 memory 使用情况。
因此,在一台一直运行的服务器上,memory cgroup 可能会达到 1w+。cadvisor 在获取 memory cgroup 时可能耗费 1s 以上的时间。在这段时间内,CPU 没法被调度给其他地方使用。
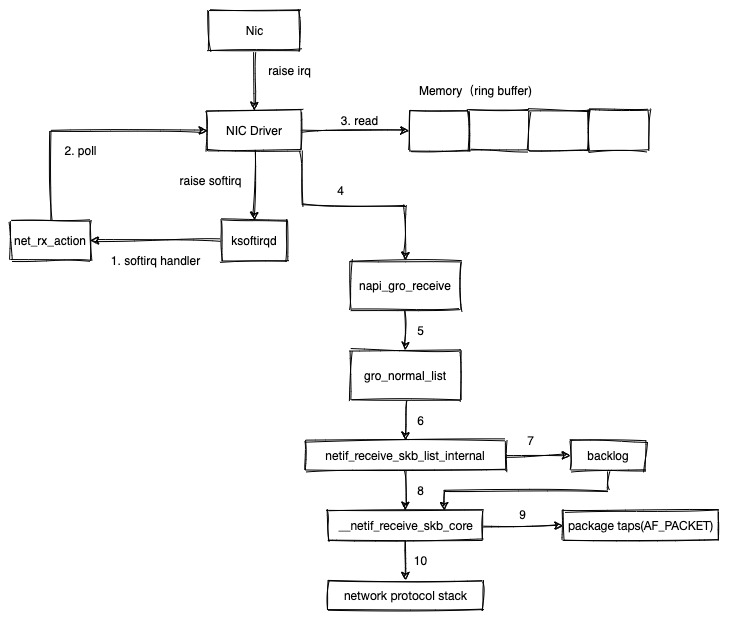
那为什么会导致网络的延迟呢?linux 网络数据包的接收,在之前的文章 linux 网络数据包接收流程(一)中整理过。数据包到达网卡后,依赖硬中断(3)+软中断(6)来触发 CPU 对数据包进行处理。
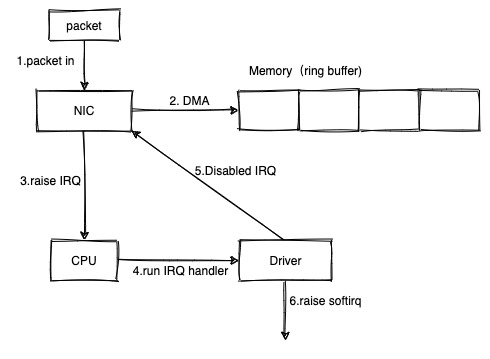
并且现在的网卡很多都是多队列的,每条队列和某个 CPU 进行绑定,由该 CPU 进行处理。因此如果这个软中断发生在 cadvisor 统计 memory cgroup,进行系统调用时,软中断的处理就可能因此而延迟。如果这个过程持续 1s+,那么引起的现象可能就是对端 tcp 出现重传。如果这个过程持续 2s+,那么因为服务本身读取 redis 的超时时间设置为 2s,就可能出现超时了。
解决方案
长期解决方案就是升级内核。在更高的版本内核中,对 cgroup memory 的计算进行了优化,这里不再会遍历所有的子 memory cgroup 进行统计了。因为本身 cgroup 就已经维护了该信息,直接读取并返回就行了。内核相关修复:https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?h=v6.2-rc7&id=dd8657b6c1cb5e65b13445b4a038736e81cf80ea
短期解决方案是周期执行这条命令:echo 3 > /proc/sys/vm/drop_caches。这会触发内核清理 PageCache, dentries 和 inodes 缓存。这里如果是 echo 1,则只清理 PageCache。echo 2,只清理 dentries 和 inodes 缓存。