1. 概述
k8s 的 apiserver 作为所有组件通信的枢纽,其重要性不言而喻。apiserver 可以对外提供基于 HTTP 的服务,那么一个请求从发出到处理,具体要经过哪些步骤呢?下面会根据代码将整个过程简单的叙述一遍,让大家可以对这个过程由大概的印象。
因为 apiserver 的代码结构并不简单,因此会尽量少的贴代码。以下分析基于 k8s 1.18
2. 请求的处理链
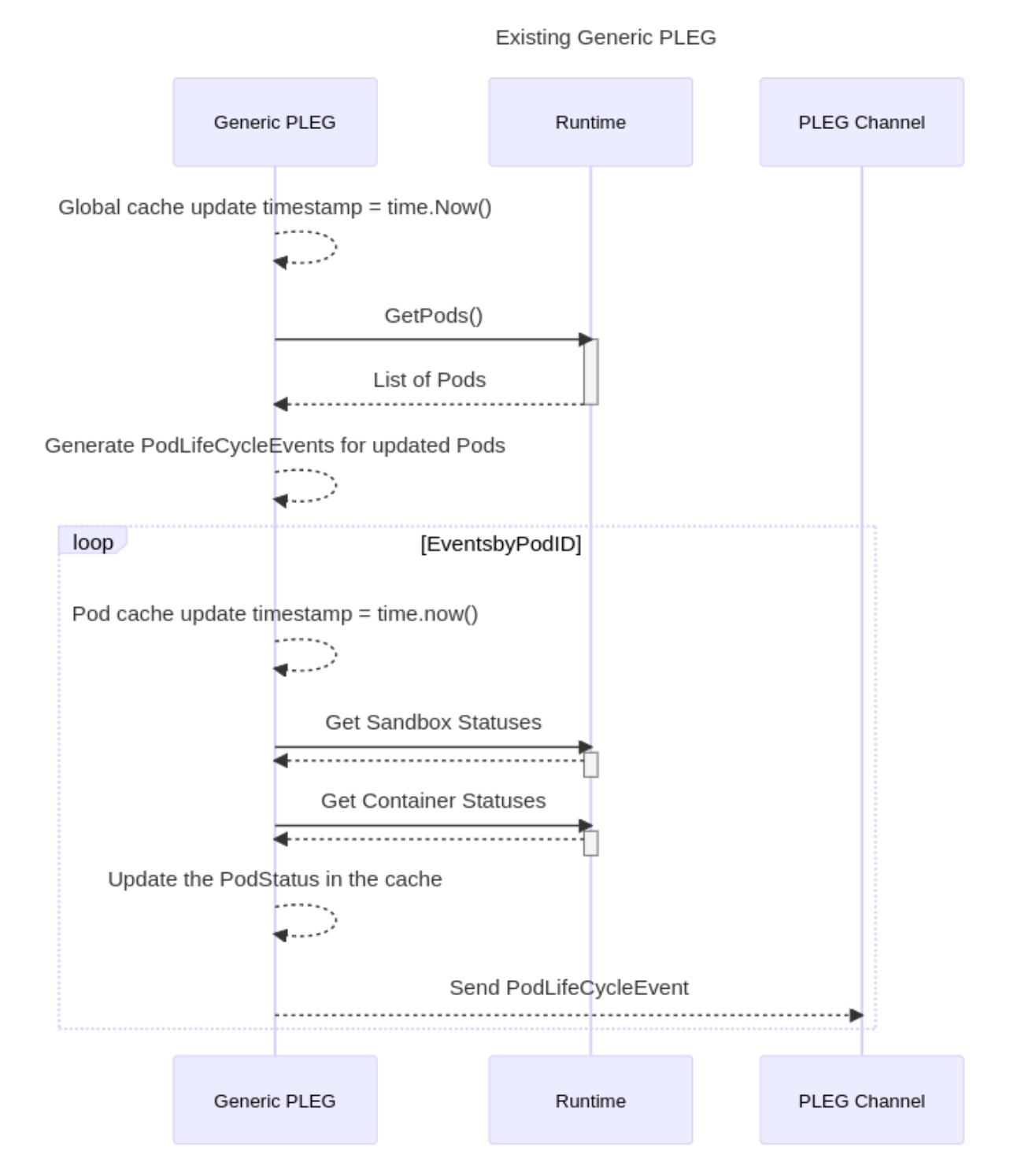
// 构建请求的处理链
func DefaultBuildHandlerChain(apiHandler http.Handler, c *Config) http.Handler {
handler := genericapifilters.WithAuthorization(apiHandler, c.Authorization.Authorizer, c.Serializer)
if c.FlowControl != nil {
handler = genericfilters.WithPriorityAndFairness(handler, c.LongRunningFunc, c.FlowControl)
} else {
handler = genericfilters.WithMaxInFlightLimit(handler, c.MaxRequestsInFlight, c.MaxMutatingRequestsInFlight, c.LongRunningFunc)
}
handler = genericapifilters.WithImpersonation(handler, c.Authorization.Authorizer, c.Serializer)
handler = genericapifilters.WithAudit(handler, c.AuditBackend, c.AuditPolicyChecker, c.LongRunningFunc)
failedHandler := genericapifilters.Unauthorized(c.Serializer, c.Authentication.SupportsBasicAuth)
failedHandler = genericapifilters.WithFailedAuthenticationAudit(failedHandler, c.AuditBackend, c.AuditPolicyChecker)
handler = genericapifilters.WithAuthentication(handler, c.Authentication.Authenticator, failedHandler, c.Authentication.APIAudiences)
handler = genericfilters.WithCORS(handler, c.CorsAllowedOriginList, nil, nil, nil, "true")
handler = genericfilters.WithTimeoutForNonLongRunningRequests(handler, c.LongRunningFunc, c.RequestTimeout)
handler = genericfilters.WithWaitGroup(handler, c.LongRunningFunc, c.HandlerChainWaitGroup)
handler = genericapifilters.WithRequestInfo(handler, c.RequestInfoResolver)
if c.SecureServing != nil && !c.SecureServing.DisableHTTP2 && c.GoawayChance > 0 {
handler = genericfilters.WithProbabilisticGoaway(handler, c.GoawayChance)
}
handler = genericfilters.WithPanicRecovery(handler)
return handler
}
这个请求的处理链是从后向前执行的。因此请求经过的 handler 为:
- PanicRecovery
- ProbabilisticGoaway
- RequestInfo
- WaitGroup
- TimeoutForNonLongRunningRequests
- CORS
- Authentication
- failedHandler: FailedAuthenticationAudit
- failedHandler: Unauthorized
- Audit
- Impersonation
- PriorityAndFairness / MaxInFlightLimit
- Authorization
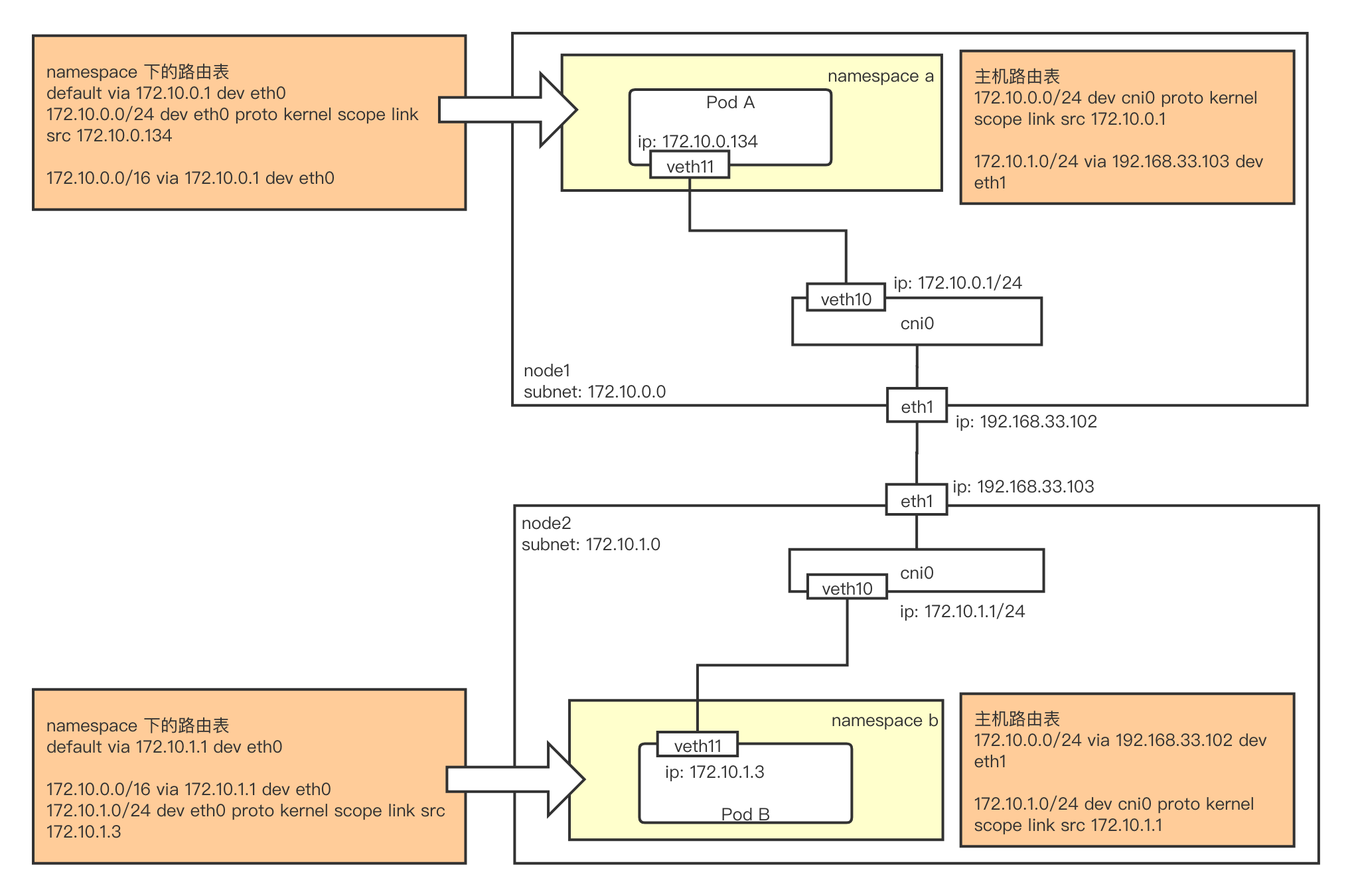
之后传递到 director,由 director 分到 gorestfulContainer 或 nonGoRestfulMux。gorestfulContainer 是 apiserver 主要部分。
director := director{
name: name,
goRestfulContainer: gorestfulContainer,
nonGoRestfulMux: nonGoRestfulMux,
}
PanicRecovery
runtime.HandleCrash 防止 panic,并打了日志记录 panic 的请求详情
ProbabilisticGoaway
因为 client 和 apiserver 是使用 http2 长连接的。这样即使 apiserver 有负载均衡,部分 client 的请求也会一直命中到同一个 apiserver 上。goaway 会配置一个很小的几率,在 apiserver 收到请求后响应 GOWAY 给 client,这样 client 就会新建一个 tcp 连接负载均衡到不同的 apiserver 上。这个几率的取值范围是 0~0.02
相关的 PR:https://github.com/kubernetes/kubernetes/pull/88567
RequestInfo
RequestInfo 会根据 HTTP 请求进行解析处理。得到以下的信息:
// RequestInfo holds information parsed from the http.Request
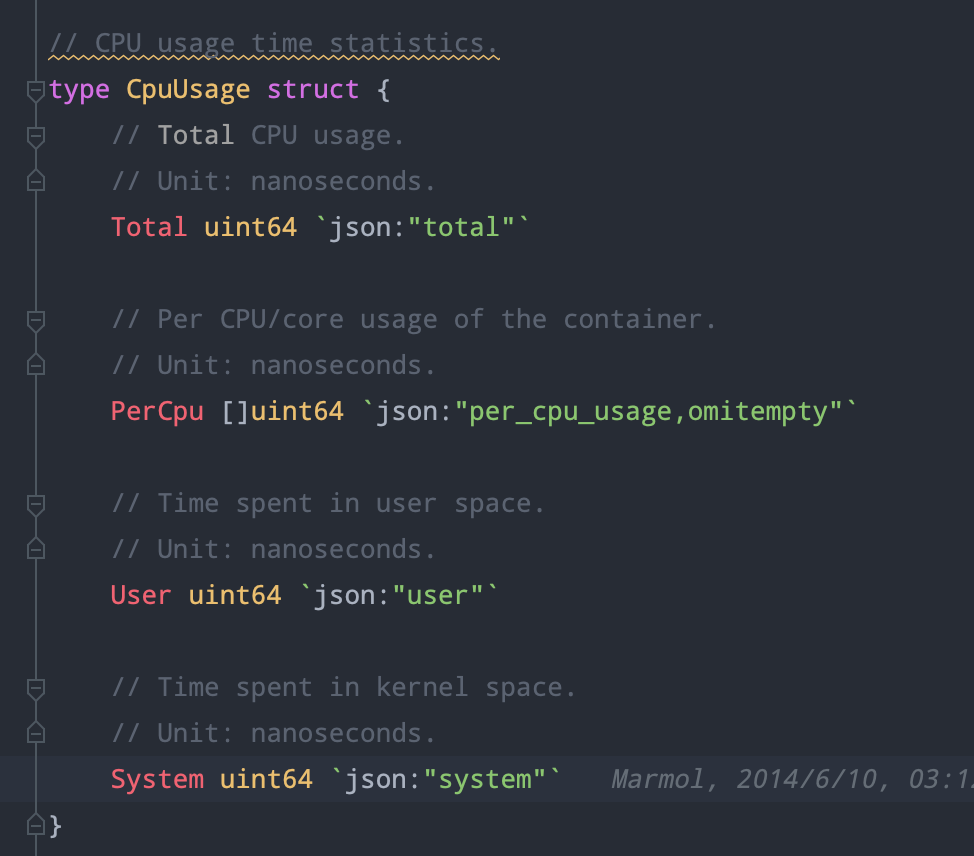
type RequestInfo struct {
// IsResourceRequest indicates whether or not the request is for an API resource or subresource
IsResourceRequest bool
// Path is the URL path of the request
Path string
// Verb is the kube verb associated with the request for API requests, not the http verb. This includes things like list and watch.
// for non-resource requests, this is the lowercase http verb
Verb string
APIPrefix string
APIGroup string
APIVersion string
Namespace string
// Resource is the name of the resource being requested. This is not the kind. For example: pods
Resource string
// Subresource is the name of the subresource being requested. This is a different resource, scoped to the parent resource, but it may have a different kind.
// For instance, /pods has the resource "pods" and the kind "Pod", while /pods/foo/status has the resource "pods", the sub resource "status", and the kind "Pod"
// (because status operates on pods). The binding resource for a pod though may be /pods/foo/binding, which has resource "pods", subresource "binding", and kind "Binding".
Subresource string
// Name is empty for some verbs, but if the request directly indicates a name (not in body content) then this field is filled in.
Name string
// Parts are the path parts for the request, always starting with /{resource}/{name}
Parts []string
}
WaitGroup
waitgroup 用来处理短连接退出的。
如何判断是不是一个长连接呢?这里是通过请求的动作或者 subresource 来判断的。watch 和 proxy 这两个动作是在 requestinfo 上通过请求的 path 来判断的。
serverConfig.LongRunningFunc = filters.BasicLongRunningRequestCheck(
sets.NewString("watch", "proxy"),
sets.NewString("attach", "exec", "proxy", "log", "portforward"),
)
// BasicLongRunningRequestCheck returns true if the given request has one of the specified verbs or one of the specified subresources, or is a profiler request.
func BasicLongRunningRequestCheck(longRunningVerbs, longRunningSubresources sets.String) apirequest.LongRunningRequestCheck {
return func(r *http.Request, requestInfo *apirequest.RequestInfo) bool {
if longRunningVerbs.Has(requestInfo.Verb) {
return true
}
if requestInfo.IsResourceRequest && longRunningSubresources.Has(requestInfo.Subresource) {
return true
}
if !requestInfo.IsResourceRequest && strings.HasPrefix(requestInfo.Path, "/debug/pprof/") {
return true
}
return false
}
}
这样之后的 handler 全部退出后,这个 waitgroup 的 handler 才会 done。这样就能实现优雅退出了。
TimeoutForNonLongRunningRequests
对于非长连接的请求,使用 ctx 的 cancel 来在超时后取消请求。
CORS
设置一些跨域的响应头
Authentication
开始认证用户。认证成功会从请求中移除 Authorization。然后将请求交给下一个 handler,否则将请求交给下一个 failed handler。
处理的方式有很多中。包括:
- Requestheader,负责从请求中取出 X-Remote-User,X-Remote-Group,X-Remote-Extra
- X509 证书校验,
- BearerToken
- WebSocket
- Anonymous: 在允许匿名的情况下
还有一部分是以插件的形式提供了认证:
- bootstrap token
-
Basic auth
- password
- OIDC
- Webhook
如果有一个认证成功的话,就认为认证成功。并且如果用户是 system:anonymous 或 用户组中包含 system:unauthenticated 和 system:authenticated。就直接返回,否则修改用户信息并返回:
r.User = &user.DefaultInfo{
Name: r.User.GetName(),
UID: r.User.GetUID(),
Groups: append(r.User.GetGroups(), user.AllAuthenticated),
Extra: r.User.GetExtra(),
}
注意到,user 现在已经属于 system:authenticated。也就是认证过了。
FailedAuthenticationAudit
这个只会在认证失败后才会执行。主要是提供了审计的功能。
Unauthorized
未授权的处理,在 FailedAuthenticationAudit 之后调用
Audit
提供请求的审计功能
Impersonation
impersonation 是一个将当前用户扮演为另外一个用户的特性,这个特性有助于管理员来测试不同用户的权限是否配置正确等等。取得 header 的 key 是:
- Impersonate-User:用户
- Impersonate-Group:组
- Impersonate-Extra-:额外信息
用户分为 service account 和 user。根据格式区分,service account 的格式是 namespace/name,否则就是当作 user 对待。
Service account 最终的格式是: system:serviceaccount:namespace:name
PriorityAndFairness / MaxInFlightLimit
如果设置了流控,就使用 PriorityAndFairness,否则使用 MaxInFlightLimit。
PriorityAndFairness:会对请求做优先级的排序。同优先级的请求会有公平性相关的控制。
MaxInFlightLimit:在给定时间内进行中不可变请求的最大数量。当超过该值时,服务将拒绝所有请求。0 值表示没有限制。(默认值 400)
参考资料:https://kubernetes.io/zh/docs/concepts/cluster-administration/flow-control/
Authorization
// AttributesRecord implements Attributes interface.
type AttributesRecord struct {
User user.Info
Verb string
Namespace string
APIGroup string
APIVersion string
Resource string
Subresource string
Name string
ResourceRequest bool
Path string
}
鉴权的时候会从 context 中取出上面这个结构体需要的信息,然后进行认证。支持的认证方式有:
- Always allow
- Always deny
- Path: 允许部分路径总是可以被访问
其他的一些常用的认证方式主要是通过插件提供:
其中 Node 专门为 kubelet 设计的,节点鉴权器允许 kubelet 执行 API 操作。包括:
读取操作:
- services
- endpoints
- nodes
- pods
- secrets、configmaps、pvcs 以及绑定到 kubelet 节点的与 pod 相关的持久卷
写入操作:
- 节点和节点状态(启用
NodeRestriction 准入插件以限制 kubelet 只能修改自己的节点)
- Pod 和 Pod 状态 (启用
NodeRestriction 准入插件以限制 kubelet 只能修改绑定到自身的 Pod)
- 事件
鉴权相关操作:
- 对于基于 TLS 的启动引导过程时使用的 certificationsigningrequests API 的读/写权限
- 为委派的身份验证/授权检查创建 tokenreviews 和 subjectaccessreviews 的能力
在将来的版本中,节点鉴权器可能会添加或删除权限,以确保 kubelet 具有正确操作所需的最小权限集。
为了获得节点鉴权器的授权,kubelet 必须使用一个凭证以表示它在 system:nodes 组中,用户名为 system:node:<nodeName>。 上述的组名和用户名格式要与 kubelet TLS 启动引导过程中为每个 kubelet 创建的标识相匹配。
director
director 的 ServeHTTP 方法定义如下,也就是会根据定义的 webservice 匹配规则进行转发。否则就调用 nonGoRestfulMux 进行处理。
func (d director) ServeHTTP(w http.ResponseWriter, req *http.Request) {
path := req.URL.Path
// check to see if our webservices want to claim this path
for _, ws := range d.goRestfulContainer.RegisteredWebServices() { q
switch {
case ws.RootPath() == "/apis":
// if we are exactly /apis or /apis/, then we need special handling in loop.
// normally these are passed to the nonGoRestfulMux, but if discovery is enabled, it will go directly.
// We can't rely on a prefix match since /apis matches everything (see the big comment on Director above)
if path == "/apis" || path == "/apis/" {
klog.V(5).Infof("%v: %v %q satisfied by gorestful with webservice %v", d.name, req.Method, path, ws.RootPath())
// don't use servemux here because gorestful servemuxes get messed up when removing webservices
// TODO fix gorestful, remove TPRs, or stop using gorestful
d.goRestfulContainer.Dispatch(w, req)
return
}
case strings.HasPrefix(path, ws.RootPath()):
// ensure an exact match or a path boundary match
if len(path) == len(ws.RootPath()) || path[len(ws.RootPath())] == '/' {
klog.V(5).Infof("%v: %v %q satisfied by gorestful with webservice %v", d.name, req.Method, path, ws.RootPath())
// don't use servemux here because gorestful servemuxes get messed up when removing webservices
// TODO fix gorestful, remove TPRs, or stop using gorestful
d.goRestfulContainer.Dispatch(w, req)
return
}
}
}
// if we didn't find a match, then we just skip gorestful altogether
klog.V(5).Infof("%v: %v %q satisfied by nonGoRestful", d.name, req.Method, path)
d.nonGoRestfulMux.ServeHTTP(w, req)
}
admission webhook
在请求真正被处理前,还差最后一步,就是我们的 admission webhook。admission 的调用是在具体的 REST 的处理代码中,在 create, update 和 delete 时,会先调用 mutate,然后再调用 validating。k8s 本身就内置了很多的 admission,以插件的形式提供,具体如下:
- AlwaysAdmit
- AlwaysPullImages
- LimitPodHardAntiAffinityTopology
- CertificateApproval/CertificateSigning/CertificateSubjectRestriction
- DefaultIngressClass
- DefaultTolerationSeconds
- ExtendedResourceToleration
- OwnerReferencesPermissionEnforcement
- ImagePolicyWebhook
- LimitRanger
- NamespaceAutoProvision
- NamespaceExists
- NodeRestriction
- TaintNodesByCondition
- PodNodeSelector
- PodPreset
- PodTolerationRestriction
- Priority
- ResourceQuota
- RuntimeClass
- PodSecurityPolicy
- SecurityContextDeny
- ServiceAccount
- PersistentVolumeLabel
- PersistentVolumeClaimResize
- DefaultStorageClass
- StorageObjectInUseProtection
3. 如何阅读 apiserver 的相关代码
我看的是仓库是 https://github.com/kubernetes/kubernetes。apiserver 的代码主要分散在以下几个位置:
- cmd/kube-apiserver: apiserver main 函数入口。主要封装了很多的启动参数。
- pkg/kubeapiserver: 提供了 kube-apiserver 和 federation-apiserve 共用的代码,但是不属于 generic API server。
- plugin/pkg: 这下面都是和认证,鉴权以及准入控制相关的插件代码
- staging/src/apiserver: 这里面是 apiserver 的核心代码。其下面的 pkg/server 是服务的启动入口。