一、概述
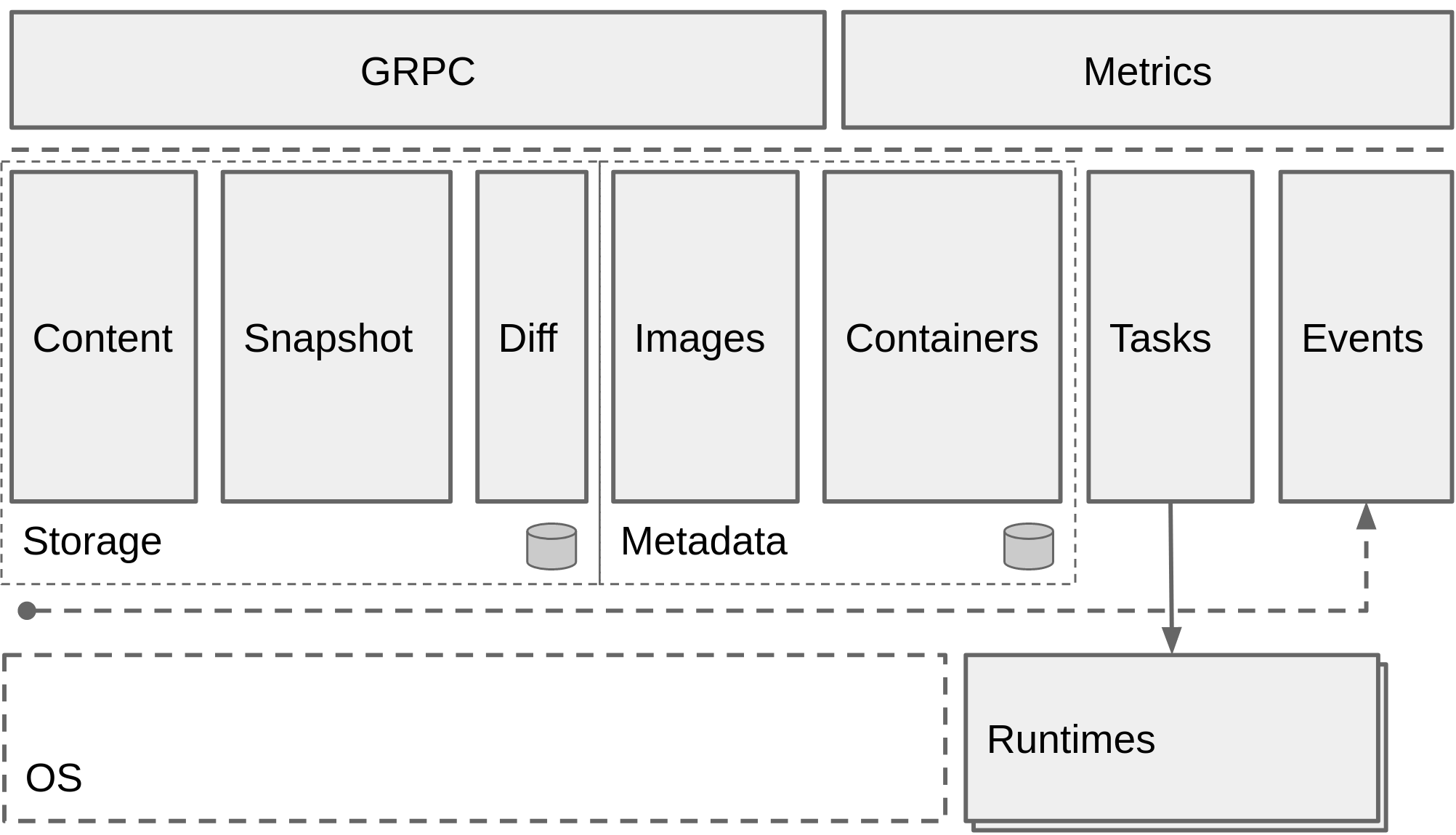
containerd 的 storage 模块负责镜像的存储,容器 rootfs 的创建等工作。其主要包括三个子模块:
- content: content 会在本地目录下保存镜像的内容。包括镜像的 manifest,config,以及镜像的层。每个层都是一个文件,格式是 tar+gzip,名称为层的 sha256sum 值。content 中存储的层都是不可变的。也就是使用的时候,并不会改变这里面的任何文件。
- snapshot: snapshot 对容器运行时的层做了抽象。分为三种类型:Commited,Active,View。其中 Active 和 View 类似,不过前者可读写,后者只读。Active 和 View 类型的 snapshot 就是我们观察到的文件系统,一般是最上层。Commited 和另外两个相反,对用户不可见,作为 Active 或 View 的 parent 使用。
- diff: diff 的主要功能有两个:Compare 和 Apply。Compare 负责计算 lower 和 upper 挂载的差异,然后使用 tar 打包差异生成新的镜像层。Apply 负责将镜像层挂载到文件系统上,生成容器运行时需要的 rootfs。
二、content 如何工作的
content 通过 GRPC 对外提供了以下接口:
// ContentServer is the server API for Content service.
type ContentServer interface {
Info(context.Context, *InfoRequest) (*InfoResponse, error)
Update(context.Context, *UpdateRequest) (*UpdateResponse, error)
List(*ListContentRequest, Content_ListServer) error
Delete(context.Context, *DeleteContentRequest) (*types.Empty, error)
Read(*ReadContentRequest, Content_ReadServer) error
Status(context.Context, *StatusRequest) (*StatusResponse, error)
ListStatuses(context.Context, *ListStatusesRequest) (*ListStatusesResponse, error)
Write(Content_WriteServer) error
Abort(context.Context, *AbortRequest) (*types.Empty, error)
}
提供了 local 和 proxy 的实现,其中 proxy 是通过 GRPC 将具体实现解耦合,因此这里并不讨论,主要关注 local 的实现方式。local 的实现中,将以上接口再分为 4 个部分:
- Manager: 提供了对 content 的查询,更新和删除操作
- Provider:提供了对指定 content 内容的读取
- IngestManager:提供了对 ingest 的状态查询和终止操作。
- Ingester:提供了对 ingest 的写入操作。
// Store combines the methods of content-oriented interfaces into a set that
// are commonly provided by complete implementations.
type Store interface {
Manager
Provider
IngestManager
Ingester
}
// Manager provides methods for inspecting, listing and removing content.
type Manager interface {
Info(ctx context.Context, dgst digest.Digest) (Info, error)
Update(ctx context.Context, info Info, fieldpaths ...string) (Info, error)
Walk(ctx context.Context, fn WalkFunc, filters ...string) error
Delete(ctx context.Context, dgst digest.Digest) error
}
// Provider provides a reader interface for specific content
type Provider interface {
ReaderAt(ctx context.Context, desc ocispec.Descriptor) (ReaderAt, error)
}
// IngestManager provides methods for managing ingests.
type IngestManager interface {
Status(ctx context.Context, ref string) (Status, error)
ListStatuses(ctx context.Context, filters ...string) ([]Status, error)
Abort(ctx context.Context, ref string) error
}
// Ingester writes content
type Ingester interface {
Writer(ctx context.Context, opts ...WriterOpt) (Writer, error)
}
为了防止理解上有歧义,这里对一些术语做一些详细的解释
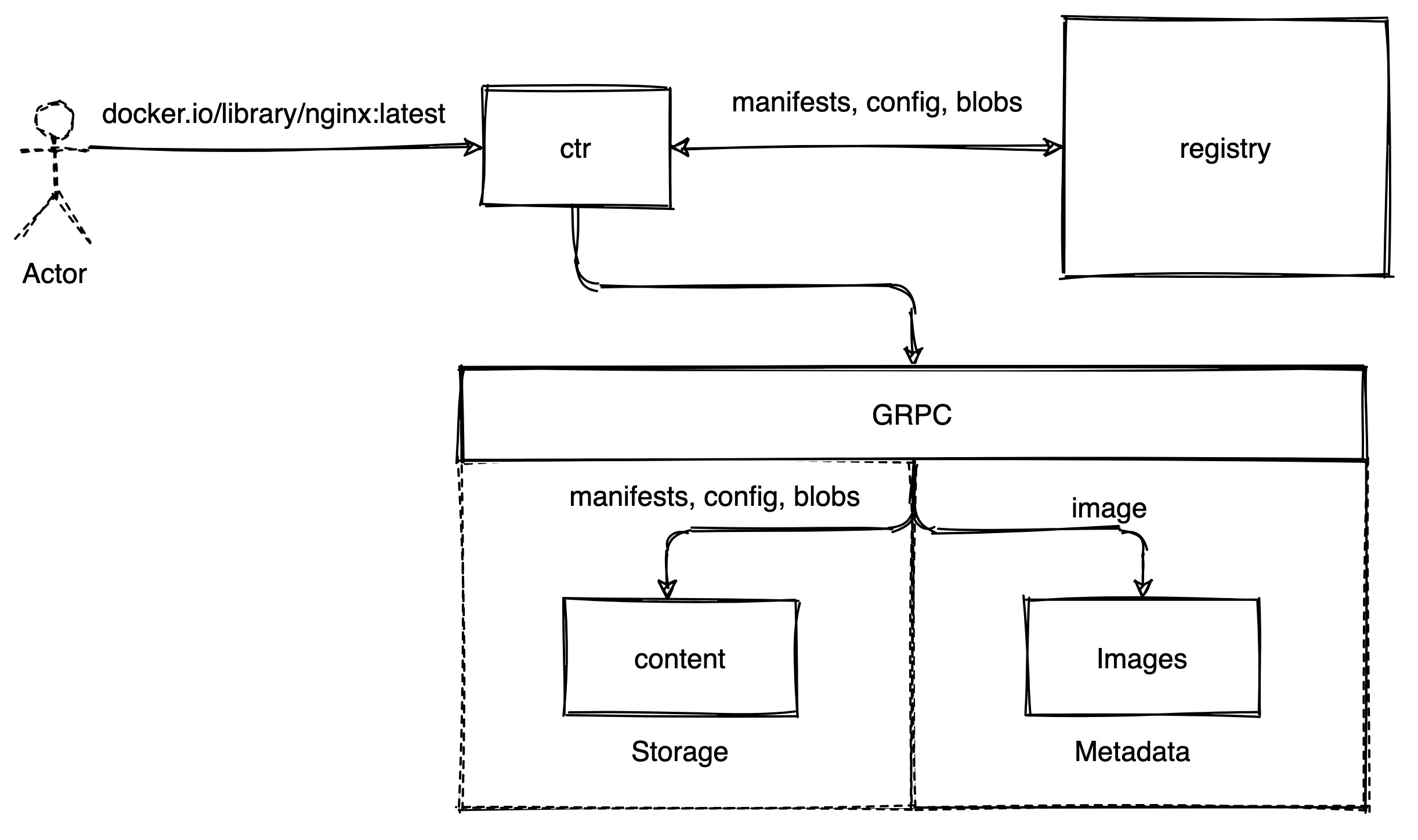
content 的使用其实已经很底层了,所以这里不准备按照 content 提供的接口进行分析,而是通过 ctr image pull docker.io/library/nginx:latest 来说明 content 的工作原理。这条命令在 cmd/ctr/commands/images/pull 下。主要执行了以下几行代码:
client, ctx, cancel, err := commands.NewClient(context)
ctx, done, err := client.WithLease(ctx)
config, err := content.NewFetchConfig(ctx, context)
img, err := content.Fetch(ctx, client, ref, config)
commands.NewClient(context)会初始化 ctr 到 containerd 的连接参数。比如:
- timeout: ctr 连接 containerd 的超时时间,默认 10s
- defaultns: containerd 使用 namespace 进行租户隔离。默认值为 default
- address: containerd 的地址,默认值是
/run/containerd/containerd.sock"
- runtime: 默认是
io.containerd.runc.v2
- platform: 指的是操作系统,CPU 架构 等
- 还要一些 GRPC 连接数据等等
client.WithLease(ctx)会在 metadata 中记录该操作,当该操作结束后,也会从 metadata 中删除。
content.NewFetchConfig(ctx, context) 用来初始化这次拉取镜像的配置
- 实例化 resolver,resolver 负责从远端 pull 到本地。containerd 使用的是
remotes/docker,应该是从 docker 那部分拿过来的代码。
- 配置 platforms
- 配置
max-concurrent-downloads,这个参数会限制同时下载的并发
content.Fetch(ctx, client, ref, config) 负责调用上一步实例化出的 client,根据 ref(镜像地址) 和 fetch config 来拉取远端镜像,然后使用 content 的接口存储到本地。
下面主要就 Fetch 展开分析。这里可以先了解一下,Fetch 会做以下的工作:
第一步获取的 manifests 内容如下:
{
"manifests": [
{
"digest": "sha256:eba373a0620f68ffdc3f217041ad25ef084475b8feb35b992574cd83698e9e3c",
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"platform": {
"architecture": "amd64",
"os": "linux"
},
"size": 1570
}
],
"mediaType": "application/vnd.docker.distribution.manifest.list.v2+json",
"schemaVersion": 2
}
第二步获取的 manifest 如下:
{
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"config": {
"mediaType": "application/vnd.docker.container.image.v1+json",
"size": 7736,
"digest": "sha256:f0b8a9a541369db503ff3b9d4fa6de561b300f7363920c2bff4577c6c24c5cf6"
},
"layers": [
{
"mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"size": 27145915,
"digest": "sha256:69692152171afee1fd341febc390747cfca2ff302f2881d8b394e786af605696"
},
{
"mediaType": "application/vnd.docker.image.rootfs.diff.tar.gzip",
"size": 26576310,
"digest": "sha256:49f7d34d62c18a321b727d5c05120130f72d1e6b8cd0f1cec9a4cca3eee0815c"
}
]
}
第三步获取的 config 如下:
{
"architecture": "amd64",
"config": {
"Hostname": "",
"Domainname": "",
"User": "",
"AttachStdin": false,
"AttachStdout": false,
"AttachStderr": false,
"ExposedPorts": {
"80/tcp": {}
},
"Tty": false,
"OpenStdin": false,
"StdinOnce": false,
"Env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"NGINX_VERSION=1.19.10",
"NJS_VERSION=0.5.3",
"PKG_RELEASE=1~buster"
],
"Cmd": [
"nginx",
"-g",
"daemon off;"
],
"Image": "sha256:f46ebb94fdef867c7f07f0b9c458ebe0ca97191f9fd6f91fd918ef71702cd755",
"Volumes": null,
"WorkingDir": "",
"Entrypoint": [
"/docker-entrypoint.sh"
],
"OnBuild": null,
"Labels": {
"maintainer": "NGINX Docker Maintainers <docker-maint@nginx.com>"
},
"StopSignal": "SIGQUIT"
},
"container": "b728dbd6862a960807b78a68f3d1d6697d954ed2b53d05b1b4c440f4aa8574a3",
"container_config": {
...
},
"created": "2021-05-12T08:40:31.711670345Z",
"docker_version": "19.03.12",
"history": [
{
"created": "2021-05-12T01:21:22.128649612Z",
"created_by": "/bin/sh -c #(nop) ADD file:7362e0e50f30ff45463ea38bb265cb8f6b7cd422eb2d09de7384efa0b59614be in / "
}
],
"os": "linux",
"rootfs": {
"type": "layers",
"diff_ids": [
"sha256:02c055ef67f5904019f43a41ea5f099996d8e7633749b6e606c400526b2c4b33",
"sha256:431f409d4c5a8f79640000705665407ff22d73e043472cb1521faa6d83afc5e8",
"sha256:4b8db2d7f35aa38ac283036f2c7a453ebfdcc8d7e83a2bf3b55bf8847f8fafaf",
"sha256:c9732df61184e9e8d08f96c6966190c59f507d8f57ea057a4610f145c59e9bc4",
"sha256:eeb14ff930d4c2c04ece429112c16a536985f0cba6b13fdb52b00853107ab9c4",
"sha256:f0f30197ccf95e395bbf4efd65ec94b9219516ae5cafe989df4cf220eb1d6dfa"
]
}
}
第四步获取的就是每个 layer 的二进制数据了。
通过上面的分析可以知道,containerd 本身并没有实现镜像的 pull,但是通过暴露 storage 中的 content 和 matadata 中 image 接口,可以在调用方实现 image pull,并将数据按照 containerd 的要求进行存储,相当于 containerd 只提供了 image 存储的实现。总结一下流程如下:
三、snapshot 如何工作的
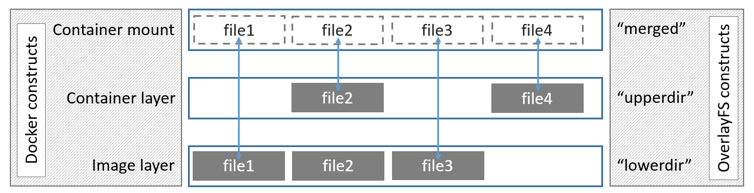
存储在 content 中的镜像层是不可变的,通常其存储格式也是没法直接使用的,常见的格式为 tar-gzip。为了使用 content 中存储的镜像层,containerd 抽象出了 snapshot,每个镜像层都会生成对应的 snapshot。
snapshot 有三种类型:committed,active 和 view。在启动容器前,镜像的每一层都会被创建成 committed snapshot,committed 表示该镜像层不可变。最后再创建出一层 active snapshot,这一层是可读写的。
下方展示了一个 nginx 镜像被 run 起来后生成的 snapshot。snapshot 之间是有 parent 关系的。第1层的 parent 为空。
# ctr snapshot ls
KEY PARENT KIND
nginx sha256:60f61ee7da08 Active
sha256:02c055ef Committed
sha256:5c3e94c8 sha256:adda6567aeaa Committed
sha256:60f61ee7 sha256:affa58c5a9d1 Committed
sha256:6b1533d4 sha256:5c3e94c8305f Committed
sha256:adda6567 sha256:02c055ef67f5 Committed
sha256:affa58c5 sha256:6b1533d42f38 Committed

下面针对执行 ctr run docker.io/library/nginx:latest nginx 来说明,不过 ctr run 还会涉及到很多 runtime 相关的内容,这里为了简单不做叙述。
当执行 ctr run 之后,会根据提供的 image 名,创建出多个 snapshot。主要的代码如下:
// 从 metadata 中查询 image 的信息
i, err := client.ImageService().Get(ctx, ref)
// 根据 image 信息初始化 image 实例
image = containerd.NewImage(client, i)
// 这个 image 是否 unpacked
unpacked, err := image.IsUnpacked(ctx, snapshotter)
if !unpacked {
// unpack 镜像
if err := image.Unpack(ctx, snapshotter); err != nil {
return nil, err
}
}
IsUnpacked 的实现如下:
func (i *image) IsUnpacked(ctx context.Context, snapshotterName string) (bool, error) {
// 获取 snapshotter 实例,默认是 overlayfs
sn, err := i.client.getSnapshotter(ctx, snapshotterName)
if err != nil {
return false, err
}
// 获取 content store 实例
cs := i.client.ContentStore()
// 这里是通过读取 image manifest,获取到 image layers 的 digest,也就是 diffs
diffs, err := i.i.RootFS(ctx, cs, i.platform)
if err != nil {
return false, err
}
// 通过 diffs 计算出最上层的 chainID
chainID := identity.ChainID(diffs)
// 因为 snapshot 的名字就是 chainID,这里通过判断最上层的 snapshot 的 chainID 是否存在
// 就可以知道这个 image 是否 unpack 了
_, err = sn.Stat(ctx, chainID.String())
if err == nil {
return true, nil
} else if !errdefs.IsNotFound(err) {
return false, err
}
return false, nil
}
chainID 的计算方式参考之前的文章:chainID 计算方式
Unpack 的实现如下,为了展示方便,代码有删减:
func (i *image) Unpack(ctx context.Context, snapshotterName string, opts ...UnpackOpt) error {
// 获取镜像的 manifest
manifest, err := i.getManifest(ctx, i.platform)
// 通过 manifest,获取 layers
layers, err := i.getLayers(ctx, i.platform, manifest)
// 默认是 overlayfs
snapshotterName, err = i.client.resolveSnapshotterName(ctx, snapshotterName)
// 获取 snapshotter 实例
sn, err := i.client.getSnapshotter(ctx, snapshotterName)
for _, layer := range layers {
// apply layer,这里是 snapshot 的工作重点
unpacked, err = rootfs.ApplyLayerWithOpts(ctx, layer, chain, sn, a, config.SnapshotOpts, config.ApplyOpts)
// chainID 的计算需要之前的 diffID,所以这里报错了每一层的 digest。
chain = append(chain, layer.Diff.Digest)
}
// 最上层的 snapshot 就是 rootfs,可以提供给 runc 使用。
rootfs := identity.ChainID(chain).String()
return err
}
Unpack 的过程,就是对每一层 apply layer 的过程。apply 一个 layer 的实现如下:
func applyLayers(ctx context.Context, layers []Layer, chain []digest.Digest, sn snapshots.Snapshotter, a diff.Applier, opts []snapshots.Opt, applyOpts []diff.ApplyOpt) error {
for {
key = fmt.Sprintf(snapshots.UnpackKeyFormat, uniquePart(), chainID)
// prepare 会创建出一个 active snapshot
mounts, err = sn.Prepare(ctx, key, parent.String(), opts...)
break
}
// 使用 diff,将这一层应用到 prepare 的 layer 上
diff, err = a.Apply(ctx, layer.Blob, mounts, applyOpts...)
// Commit 会在 metadata 中将这个 snapshot 标记为 committed。
// 对于 device mapper 设备,还会额外的使这个 snapshot 挂载不可见。
if err = sn.Commit(ctx, chainID.String(), key, opts...); err != nil {
err = errors.Wrapf(err, "failed to commit snapshot %s", key)
return err
}
return nil
}
以上就是 snapshotter 通过 image layers 创建出 snapshots 的过程。不过这上面创建的都是 committed snapshot。所以在这之后还会单独在这之上创建出一个 active snapshot 供容器读写。
// WithNewSnapshot allocates a new snapshot to be used by the container as the
// root filesystem in read-write mode
func WithNewSnapshot(id string, i Image, opts ...snapshots.Opt) NewContainerOpts {
return func(ctx context.Context, client *Client, c *containers.Container) error {
diffIDs, err := i.RootFS(ctx)
if err != nil {
return err
}
parent := identity.ChainID(diffIDs).String()
c.Snapshotter, err = client.resolveSnapshotterName(ctx, c.Snapshotter)
if err != nil {
return err
}
s, err := client.getSnapshotter(ctx, c.Snapshotter)
if err != nil {
return err
}
if _, err := s.Prepare(ctx, id, parent, opts...); err != nil {
return err
}
c.SnapshotKey = id
c.Image = i.Name()
return nil
}
}
四、diff 如何工作的
在上面对 content 和 snapshot 进行一些分析后,已经清楚了镜像的层是如何存储的,以及使用镜像是什么样的一个过程。但这其中还有两个细节没有说明:
- 一个 image layer 如何被 mount 成一个 snapshot。
- 一个 snapshot 如何被压缩成一个 image layer
这里就是 diff 子模块的作用了。diff 对外提供了两个接口:
在说明 Diff 之前,需要先提一下 OCI 中 image spec 中的一个例子。假设现在有两个文件夹 rootfs-c9d-v1/ and rootfs-c9d-v1.s1/。对其进行字典序的递归比较,发现的变动如下:
Added: /etc/my-app.d/
Added: /etc/my-app.d/default.cfg
Modified: /bin/my-app-tools
Deleted: /etc/my-app-config
那么使用 OCI 的规范打包出来就是:
./etc/my-app.d/
./etc/my-app.d/default.cfg
./bin/my-app-tools
./etc/.wh.my-app-config
删除的文件使用 .wh. 前缀来表示。
那么 Diff 的时候,主要就是对 snapshot 和其 parent 做比较,比较时使用字典序来 walk dir。然后生成的 tar 包中,对 added 和 modified 文件,只需打包最新的即可。对 deleted 文件,生成 .wh.* 来代替。
在 Apply 的时候,如果是 .wh. 前缀的文件,就根据所使用文件系统的特点来生成,比如 overlayfs 中使用 whiteout 文件来表示删除。非 .wh. 文件原样输出即可。