1. 概述
IPv6 全称是 Internet Protocol Version 6,不过虽然是叫 Version 6,事实上是网络层协议的第二代标准协议。其出现主要是为了解决 IPv4 在实际应用场景中存在的一些缺陷。
与 IPv4 的优缺点对比
摘抄自:华为 IPv6 技术白皮书
| 问题 | IPv4缺陷 | IPv6优势 |
|---|---|---|
| 地址空间 | IPv4 地址只有32位,因此总共可表示的地址在 43 亿左右。另外由于历史原因,IP 地址的分配也非常不均衡:美国占全球地址 空间的一半左右,而欧洲则相对匮乏;亚太地区则更加匮乏。IPv4 中用来解决地址短缺的方法有:CIDR 和 NAT。不过这两种方案都有其本身的缺点。 | IPv6 有 128 位。理论上总共可以支持 43亿x43亿x43亿x43亿的地址。 |
| 报文格式 | IPv4报头包含可选字段Options,内 容涉及Security、Timestamp、 Record route等,这些Options可以将 IPv4报头长度从20字节扩充到60字 节。携带这些Options的IPv4报文在 转发过程中往往需要中间路由转发 设备进行软件处理,对于性能是个 很大的消耗,因此实际中也很少使 用。 | IPv6和IPv4相比,去除了IHL、 Identifier、Flag、Fragment Offset、Header Checksum、 Option、Paddiing域,只增加了流 标签域,因此IPv6报文头的处理 较IPv4更为简化,提高了处理效 率。另外,IPv6为了更好支持各 种选项处理,提出了扩展头的概 念,新增选项时不必修改现有结 构,理论上可以无限扩展,体现 了优异的灵活性。 |
| 自动配置和重新编制 | 由于IPv4地址只有32比特,并且地 址分配不均衡,导致在网络扩容或 重新部署时,经常需要重新分配IP 地址,因此需要能够进行自动配置 和重新编址,以减少维护工作量。 目前IPv4的自动配置和重新编址机 制主要依靠DHCP协议。 | IPv6协议内置支持通过地址自动 配置方式使主机自动发现网络并 获取IPv6地址,大大提高了内部 网络的可管理性。 |
| 路由聚合 | 由于IPv4发展初期的分配规划问 题,造成许多IPv4地址分配不连 续,不能有效聚合路由。日益庞大 的路由表耗用大量内存,对设备成 本和转发效率产生影响,这一问题 促使设备制造商不断升级其产品, 以提高路由寻址和转发性能。 | 巨大的地址空间使得IPv6可以方 便的进行层次化网络部署。层次 化的网络结构可以方便的进行路 由聚合,提高了路由转发效率。 |
| 端对端安全 | IPv4协议制定时并没有仔细针对安全性进行设计,因此固有的框架结构并不能支持端到端的安全。 | IPv6中,网络层支持IPSec的认证 和加密,支持端到端的安全。 |
| QoS | 随着网络会议、网络电话、网络电 视迅速普及与使用,客户要求有更 好的QoS来保障这些音视频实时转 发。IPv4并没有专门的手段对QoS 进行支持。 | IPv6新增了流标记域,提供QoS 保证。 |
| 支持移动特性 | 随着Internet的发展,移动IPv4出现 了一些问题,比如:三角路由,源 地址过滤等。 | IPv6协议规定必须支持移动特 性。和移动IPv4相比,移动IPv6 使用邻居发现功能可直接实现外 地网络的发现并得到转交地址, 而不必使用外地代理。同时,利 用路由扩展头和目的地址扩展头 移动节点和对等节点之间可以直 接通信,解决了移动IPv4的三角 路由、源地址过滤问题,移动通 信处理效率更高且对应用层透 明。 |
IPv6 地址
表示方法
IPv6 总共有 128 位,通过分为8组,每组 16 位,由 4 个十六进制数表示。每组之间由冒号分隔。如:FC00:0000:130F:0000:0000:09C0:876A:130B。为了方便书写,提供了一些压缩后的写法:
- 可以省略前缀0。所以这个地址还可以写成:
FC00:0:130F:0:0:9C0:876A:130B。 - 地址中包含的连续两个或多个均为0的组,可以用双冒号”::”代替。所以进一步缩写成:
FC00:0:130F::9C0:876A:130B。不过需要注意的是,一个 IPv6 地址中只能有一个 “::”,因为如果有多个的话,就无法辨别出每个 “::” 代表几组 0。
地址结构
类似 IPv4 的设计,一个 IPv6 地址也是由两部分组成:
- 网络前缀:n 位,相当于 IPv4 的网络号。
- 接口标识:128-n位,相当于 IPv4 地址中的主机号。
地址分类
IPv6 地址分为单播地址,任播地址,组播地址。相比于 IPv4,取消了广播地址,以更丰富的组播地址代替,同时增加了任播地址。
单播地址
单播地址用来表示一个节点的一个网络接口的地址。有以下几种单播地址:
| 类型 | 说明 |
|---|---|
| 未指定地址 | 指 ::/128。该地址表示讴歌接口或者节点还没有 IP 地址。 |
| 环回地址 | 指::1/128。与 IPv4 中的 127.0.0.1 作用相同 |
| 全球单播地址 | 类似于 IPv4 中的单播地址。由 全球路由前缀(Global routing prefix,至少48位)+子网ID(Subnet ID)+接口标识(Interface ID)组成。全球路由前缀由提供商指定给一个组织机构,因此也可以起到聚合路由的作用。 |
| 链路本地地址 | 链路本地地址是 IPv6 中的应用范围受限制的地址类型,只能在连接到同一本地链 路的节点之间使用。它使用了特定的本地链路前缀FE80::/10(最高10位值为 1111111010),同时将接口标识添加在后面作为地址的低64比特。当一个节点启动IPv6协议栈时,启动时节点的每个接口会自动配置一个链路本地 地址(其固定的前缀+EUI-64规则形成的接口标识)。在 IPv4 中,链路本地地址为 169.254.0.0/16 |
| 唯一本地地址 | 唯一本地地址是另一种应用范围受限的地址,它仅能在一个站点内使用。由于本地站点地址的废除(RFC3879),唯一本地地址被用来代替本地站点地址。唯一本地地址的作用类似于IPv4中的私网地址,任何没有申请到提供商分配的全 球单播地址的组织机构都可以使用唯一本地地址。唯一本地地址只能在本地网络内部被路由转发而不会在全球网络中被路由转发。唯一本地地址的固定前缀为FC00::/7,二进制表示为 1111 110。 |
任播地址
任播地址一般用来表示一组节点上的接口,当数据包发往任播地址时,中间路由设备会将数据包发往最近的一个节点上的接口。所以可以看出,任播地址是被设计用来给多个主机或者节点提供相同服务时提供冗余功能和负载均衡功能的。不过目前实际应用中,任播地址只能分配给路由设备,并不能应用于主机等设备。并且任播地址不能作为 IPv6 报文的源地址。
任播地址并没有单独的地址空间,和单播地址使用相同的地址空间。
组播地址
IPv6的组播与IPv4相同,用来标识一组接口,一般这些接口属于不同的节点。一个节点 可能属于0到多个组播组。发往组播地址的报文被组播地址标识的所有接口接收。例如 组播地址FF02::1表示链路本地范围的所有节点,组播地址FF02::2表示链路本地范围的 所有路由器。
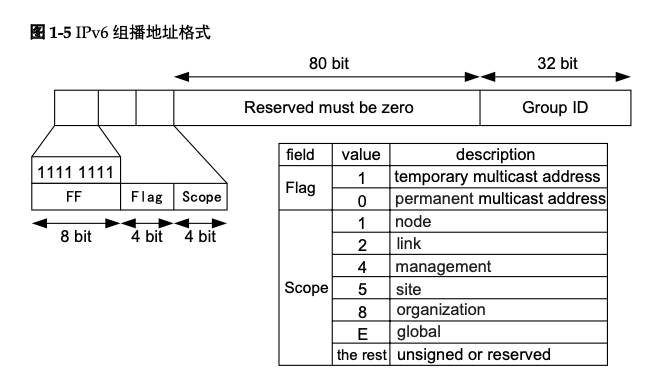
一个IPv6组播地址由前缀,标志(Flag)字段、范围(Scope)字段以及组播组ID (Global ID)4个部分组成:
- 前缀:IPv6组播地址的前缀是FF00::/8。
-
标志字段(Flag):长度4bit,目前只使用了最后一个比特(前三位必须置0), 当该位值为0时,表示当前的组播地址是由IANA所分配的一个永久分配地址;当 该值为1时,表示当前的组播地址是一个临时组播地址(非永久分配地址)。
-
范围字段(Scope):长度4bit,用来限制组播数据流在网络中发送的范围,该字 段取值和含义的对应关系如图1-5所示。
-
组播组ID(Group ID):长度112bit,用以标识组播组。目前,RFC2373并没有将 所有的112位都定义成组标识,而是建议仅使用该112位的最低32位作为组播组 ID,将剩余的80位都置0。这样每个组播组ID都映射到一个唯一的以太网组播 MAC地址(RFC2464)。
被请求节点组播地址通过节点的单播或任播地址生成。当一个节点具有了单播或任播地址,就会对应生成一个被请求节点组播地址,并且加入这个组播组。一个单播地址或任播地址对应一个被请求节点组播地址。该地址主要用于邻居发现机制和地址重复检测功能。
IPv6中没有广播地址,也不使用ARP。但是仍然需要从IP地址解析到MAC地址的 功能。在IPv6中,这个功能通过邻居请求NS(Neighbor Solicitation)报文完成。 当一个节点需要解析某个IPv6地址对应的MAC地址时,会发送NS报文,该报文目的IP就是需要解析的IPv6地址对应的被请求节点组播地址;只有具有该组播地 址的节点会检查处理。
被请求节点组播地址由前缀FF02::1:FF00:0/104和单播地址的最后24位组成。
IPv6 报文格式
IPv6 除了在大小上做了变动,也针对 IPv4 报文格式在实际应用场景中的设计不合理之处做了优化。IPv6 报文主要由三部分组成:
- IPv6 基本报头:8个字段,固定为 40 字节。
- IPv6 扩展报头:扩展报头是链式结构的,理论上可无限扩展
- 上层协议数据单元:一般由上层协议报头和它的有效载荷构成,有效载荷可以是一个 ICMPv6 报文、一个 TCP 报文或一个 UDP 报文。
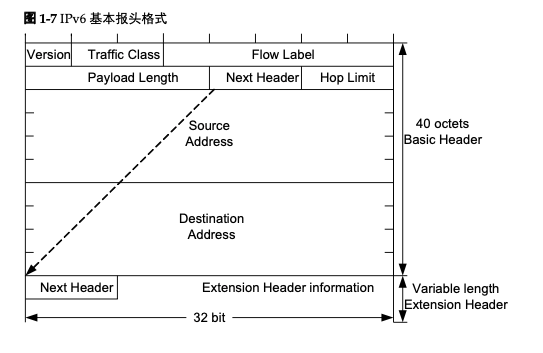
一个 IPv6 的基本报头格式如下:
这些字段的解释如下:
- Version:版本号,长度为4bit。对于IPv6,该值为6。
-
Traffic Class:流类别,长度为8bit。等同于IPv4中的TOS字段,表示IPv6数据报的 类或优先级,主要应用于QoS。
-
Flow Label:流标签,长度为20bit。IPv6中的新增字段,用于区分实时流量,不同 的流标签+源地址可以唯一确定一条数据流,中间网络设备可以根据这些信息更加 高效率的区分数据流。
-
Payload Length:有效载荷长度,长度为16bit。有效载荷是指紧跟IPv6报头的数据 报的其它部分(即扩展报头和上层协议数据单元)。该字段只能表示最大长度为 65535字节的有效载荷。如果有效载荷的长度超过这个值,该字段会置0,而有效 载荷的长度用逐跳选项扩展报头中的超大有效载荷选项来表示。
-
Next Header:下一个报头,长度为8bit。该字段定义紧跟在IPv6报头后面的第一个 扩展报头(如果存在)的类型,或者上层协议数据单元中的协议类型。
-
Hop Limit:跳数限制,长度为8bit。该字段类似于IPv4中的Time to Live字段,它 定义了IP数据报所能经过的最大跳数。每经过一个设备,该数值减去1,当该字段 的值为0时,数据报将被丢弃。
-
Source Address:源地址,长度为128bit。表示发送方的地址。
- Destination Address:目的地址,长度为128bit。表示接收方的地址。
通过上述描述可以知道,IPv6 的基本报头相比于 IPv4 的报头做了简化,去除了IHL、identifiers、Flags、Fragment Offset、Header Checksum、 Options、Paddiing域,只增了流标签域。这样的设计可以提升路由设备对数据的处理性能。
在IPv4中,IPv4报头包含可选字段Options,内容涉及security、Timestamp、Record route 等,这些Options可以将IPv4报头长度从20字节扩充到60字节。在转发过程中,处理携带这些Options的IPv4报文会占用设备很大的资源,因此实际中也很少使用。
IPv6将这些Options从IPv6基本报头中剥离,放到了扩展报头中,扩展报头被置于IPv6 报头和上层协议数据单元之间。一个IPv6报文可以包含0个、1个或多个扩展报头,仅 当需要设备或目的节点做某些特殊处理时,才由发送方添加一个或多个扩展头。与 IPv4不同,IPv6扩展头长度任意,不受40字节限制,这样便于日后扩充新增选项,这一特征加上选项的处理方式使得IPv6选项能得以真正的利用。但是为了提高处理选项头 和传输层协议的性能,扩展报头总是8字节长度的整数倍。
当使用多个扩展报头时,前面报头的Next Header字段指明下一个扩展报头的类型,这 样就形成了链状的报头列表。目前,RFC 2460中定义了6个IPv6扩展头:逐跳选项报头、目的选项报头、路由报头、分段报头、认证报头、封装安全净载报头。
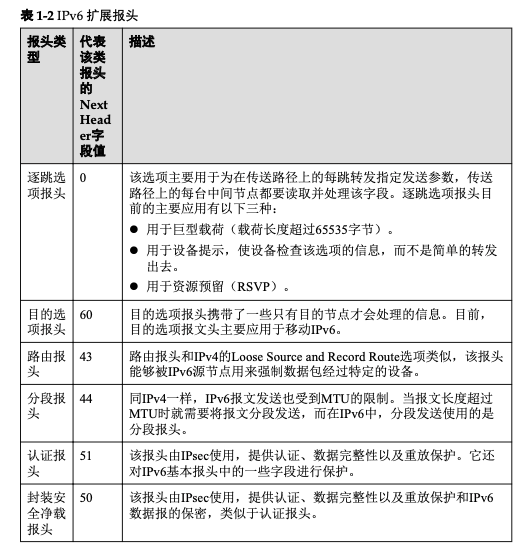
ICMPv6
ICMPv6(Internet Control Message Protocol for the IPv6)是IPv6的基础协议之一。
在IPv4中,Internet控制报文协议ICMP(Internet Control Message Protocol)向源节点报 告关于向目的地传输IP数据包过程中的错误和信息。它为诊断、信息和管理目的定义 了一些消息,如:目的不可达、数据包超长、超时、回应请求和回应应答等。在IPv6 中,ICMPv6除了提供ICMPv4常用的功能之外,还是其它一些功能的基础,如邻接点 发现、无状态地址配置(包括重复地址检测)、PMTU发现等。
ICMPv6的协议类型号(即IPv6报文中的Next Header字段的值)为58。
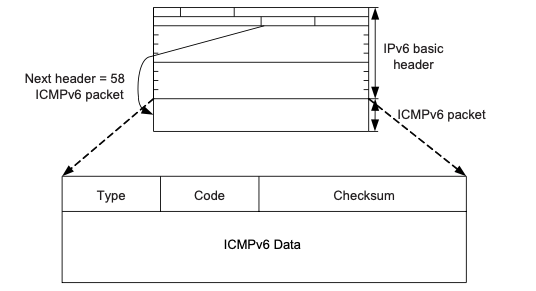
报文中字段解释如下:
- Type:表明消息的类型,0至127表示差错报文类型,128至255表示消息报文类型。
-
Code:表示此消息类型细分的类型。
- Checksum:表示ICMPv6报文的校验和。
邻居发现
邻居发现协议NDP(Neighbor Discovery Protocol)是IPv6协议体系中一个重要的基础协 议。邻居发现协议替代了IPv4的ARP(Address Resolution Protocol)和ICMP路由器发现 (Router Discovery),它定义了使用ICMPv6报文实现地址解析,跟踪邻居状态,重复 地址检测,路由器发现以及重定向等功能。
地址解析
邻居发现协议 NDP(Neighbor Discovery Protocol) 是基于 ICMPv6 的一个三层协议,用来取代 IPv4 的 ARP 协议。其以太网协议类型为 0x86DD。地址解析过程中使用了两种 ICMPv6 报文:邻居请求报文 NS(Neighbor Solicitation) 和邻居通告报文 NA(Neighbor Advertisement)。
- NS 报文:Type 字段值为 135,Code 字段值为 0,在地址解析中的作用类似于 IPv4 中的 ARP 请求报文。
- NA 报文:Type 字段值为 136,Code 字段值为0,在地址解析中的作用类似于 IPv4 中的 ARP 响应报文。
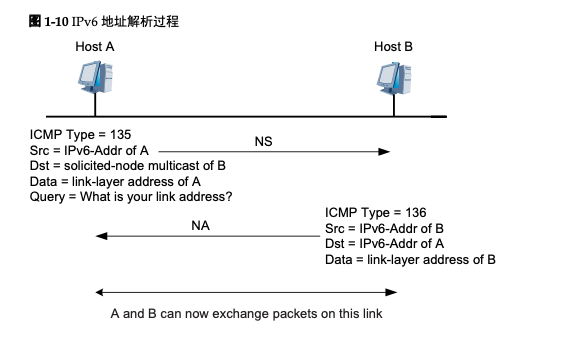
Host A在向Host B发送报文之前它必须要解析出Host B的链路层地址,所以首先Host A 会发送一个NS报文,其中源地址为Host A的IPv6地址,目的地址为Host B的被请求节 点组播地址,需要解析的目标IP为Host B的IPv6地址,这就表示Host A想要知道Host B 的链路层地址。同时需要指出的是,在NS报文的Options字段中还携带了Host A的链路 层地址。
当Host B接收到了NS报文之后,就会回应NA报文,其中源地址为Host B的IPv6地址, 目的地址为Host A的IPv6地址(使用NS报文中的Host A的链路层地址进行单播),Host B的链路层地址被放在Options字段中。这样就完成了一个地址解析的过程。
跟踪邻居状态
通过邻居或到达邻居的通信,会因各种原因而中断,包括硬件故障、接口卡的热插入 等。如果目的地失效,则恢复是不可能的,通信失败;如果路径失效,则恢复是可能 的。 因此节点需要维护一张邻居表,每个邻居都有相应的状态,状态之间可以迁移。
RFC2461中定义了5种邻居状态,分别是:未完成(Incomplete)、可达 (Reachable)、陈旧(Stale)、延迟(Delay)、探查(Probe)
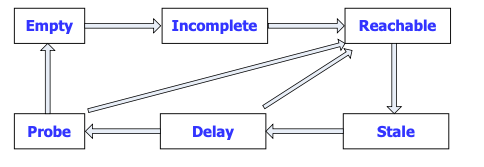
下面以A、B两个邻居节点之间相互通信过程中A节点的邻居状态变化为例(假设A、B 之前从未通信),说明邻居状态迁移的过程。
- A先发送NS报文,并生成缓存条目,此时,邻居状态为Incomplete。
- 若B回复NA报文,则邻居状态由Incomplete变为Reachable,否则固定时间后邻居状态由Incomplete变为Empty,即删除表项。
- 经过邻居可达时间,邻居状态由Reachable变为Stale,即不确定邻居节点的可达性。
- 如果在Reachable状态,A收到B的非请求NA报文,且报文中携带的B的链路层地址和表项中不同,则邻居状态马上变为Stale。
- 在STALE状态到达老化时间后进入Delay状态。
- 在经过一段固定时间(5秒)后,邻居状态由Delay变为Probe,其间若有NA应答, 则邻居状态由Delay变为Reachable。
- 在Probe状态,A每隔一定时间间隔(1秒)发送单播NS,发送固定次数(3次) 后,有应答则邻居状态变为Reachable,否则邻居状态变为Empty,即删除表项。
重复地址检测
重复地址检测DAD(Duplicate Address Detect)是在接口使用某个IPv6单播地址之前进 行的,主要是为了探测是否有其它的节点使用了该地址。尤其是在地址自动配置的时 候,进行DAD检测是很必要的。 一个IPv6单播地址在分配给一个接口之后且通过重复 地址检测之前称为试验地址(Tentative Address)。此时该接口不能使用这个试验地址 进行单播通信,但是仍然会加入两个组播组:ALL-NODES组播组和试验地址所对应的 Solicited-Node组播组。
IPv6重复地址检测技术和IPv4中的免费ARP类似:节点向试验地址所对应的Solicited- Node组播组发送NS报文。NS报文中目标地址即为该试验地址。如果收到某个其他站点 回应的NA报文,就证明该地址已被网络上使用,节点将不能使用该试验地址通讯。
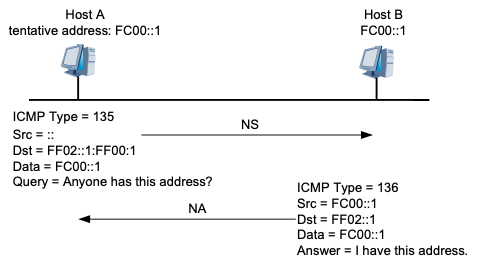
Host A的IPv6地址FC00::1为新配置地址,即FC00::1为Host A的试验地址。Host A向 FC00::1的Solicited-Node组播组发送一个以FC00::1为请求的目标地址的NS报文进行重 复地址检测,由于FC00::1并未正式指定,所以NS报文的源地址为未指定地址。当Host B收到该NS报文后,有两种处理方法:
- 如果Host B发现FC00::1是自身的一个试验地址,则Host B放弃使用这个地址作为 接口地址,并且不会发送NA报文。
-
如果Host B发现FC00::1是一个已经正常使用的地址,Host B会向FF02::1发送一个 NA报文,该消息中会包含FC00::1。这样,Host A收到这个消息后就会发现自身的 试验地址是重复的。Host A上该试验地址不生效,被标识为duplicated状态。
路由器发现
路由器发现功能用来发现与本地链路相连的设备,并获取与地址自动配置相关的前缀和其他配置参数。
在IPv6中,IPv6地址可以支持无状态的自动配置,即主机通过某种机制获取网络前缀信 息,然后主机自己生成地址的接口标识部分。路由器发现功能是IPv6地址自动配置功 能的基础,主要通过以下两种报文实现:
- 路由器通告RA(Router Advertisement)报文:每台设备为了让二层网络上的主机 和设备知道自己的存在,定时都会组播发送RA报文,RA报文中会带有网络前缀 信息,及其他一些标志位信息。RA报文的Type字段值为134。
-
路由器请求RS(Router Solicitation)报文:很多情况下主机接入网络后希望尽快 获取网络前缀进行通信,此时主机可以立刻发送RS报文,网络上的设备将回应RA 报文。RS报文的Tpye字段值为133。
重定向
当网关设备发现报文从其它网关设备转发更好,它就会发送重定向报文告知报文的发 送者,让报文发送者选择另一个网关设备。重定向报文也承载在ICMPv6报文中,其 Type字段值为137,报文中会携带更好的路径下一跳地址和需要重定向转发的报文的目 的地址等信息。
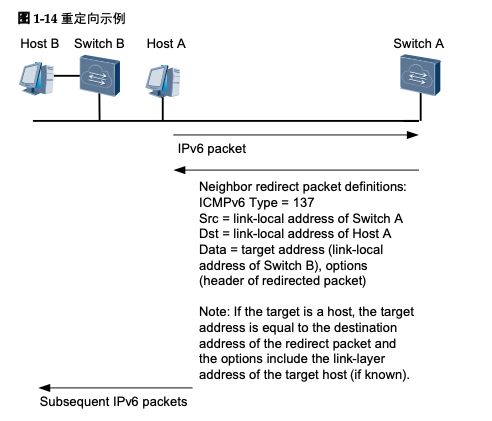
Host A需要和Host B通信,Host A的默认网关设备是Switch A,当Host A发送报文给 Host B时报文会被送到Switch A。Switch A接收到Host A发送的报文以后会发现实际上 Host A直接发送给Switch B更好,它将发送一个重定向报文给主机A,其中报文中更好 的路径下一跳地址为Switch B,Destination Address为Host B。Host A接收到了重定向报 文之后,会在默认路由表中添加一个主机路由,以后发往Host B的报文就直接发送给 Switch B。
当设备收到一个报文后,只有在如下情况下,设备会向报文发送者发送重定向报文:
- 报文的目的地址不是一个组播地址。
- 报文并非通过路由转发给设备。
- 经过路由计算后,路由的下一跳出接口是接收报文的接口。
- 设备发现报文的最佳下一跳IP地址和报文的源IP地址处于同一网段。
- 设备检查报文的源地址,发现自身的邻居表项中有用该地址作为全球单播地址或链路本地地址的邻居存在。
Path MTU
在IPv4中,报文如果过大,必须要分片进行发送,所以在每个节点发送报文之前,设备都会根据发送接口的最大传输单元MTU(Maximum Transmission Unit)来对报文进 行分片。但是在IPv6中,为了减少中间转发设备的处理压力,中间转发设备不对IPv6报文进行分片,报文的分片将在源节点进行。当中间转发设备的接口收到一个报文后, 如果发现报文长度比转发接口的MTU值大,则会将其丢弃;同时将转发接口的MTU值 通过ICMPv6报文的“Packet Too Big”消息发给源端主机,源端主机以该值重新发送 IPv6报文,这样带来了额外流量开销。PMTU发现协议可以动态发现整条传输路径上各 链路的MTU值,减少由于重传带来的额外流量开销。
PMTU协议是通过ICMPv6的Packet Too Big报文来完成的。首先源节点假设PMTU就是 其出接口的MTU,发出一个试探性的报文,当转发路径上存在一个小于当前假设的 PMTU时,转发设备就会向源节点发送Packet Too Big报文,并且携带自己的MTU值, 此后源节点将PMTU的假设值更改为新收到的MTU值继续发送报文。如此反复,直到 报文到达目的地之后,源节点就能知道到达目的地的PMTU了。
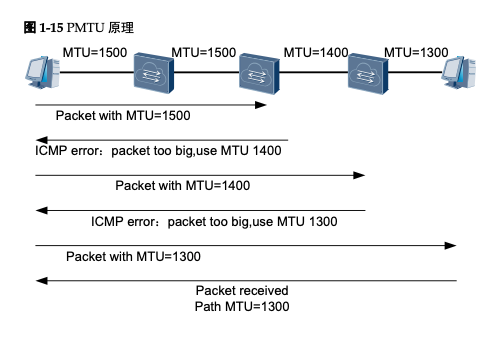
整条传输路径需要通过4条链路,每条链路的MTU分别是1500、1500、1400、1300,当 源节点发送一个分片报文的时候,首先按照PMTU为1500进行分片并发送分片报文,当 到达MTU为1400的出接口时,设备返回Packet Too Big错误,同时携带MTU值为1400的 信息。源节点接收到之后会将报文重新按照PMTU为1400进行分片并再次发送一个分片 报文,当分片报文到达MTU值为1300的出接口时,同样返回Packet Too Big错误,携带 MTU值为1300的信息。之后源节点重新按照PMTU为1300进行分片并发送分片报文, 最终到达目的地,这样就找到了该路径的PMTU。
Linux IPv6
| 条目 | ipv4 | ipv6 |
|---|---|---|
| sysctl 配置项 | net.ipv4.conf | net.ipv6.conf |
| ip 地址 | 通过 ip a查看时可以看到 inet 后面的就是 ipv4 地址。 |
通过 ip a查看时可以看到 inet6 后面的就是 ipv6 地址。一般会有多个,scope global 的是全局唯一单播地址或唯一本地地址(fc或fd开头),scope link 是链路本地地址(fe80 开头)。 |
| 抓包 | tcpdump icmp/ tcpdump ip | tcpdump icmp6 / tcpdump ip6 |
| ping | ping | ping6 或 ping -6 |
| traceroute6 | traceroute | traceroute6 |
| 邻居地址解析 | arping | ndisc |
| 路由表 | ip r | ip -6 r |
| 邻居地址表 | ip neigh 或 arp -n | ip -6 neigh |
| DNS 解析 | dig | dig -6 |
Kubernetes 的 IPv4/IPv6 双栈
IPv4/IPv6 双栈是由 IPv4 向 IPv6 过渡阶段的一种解决方案,双栈即一个网络接口同时拥有 IPv4 和 IPv6 的地址,这样在和远端通信时,如果远端支持 IPv6,就使用 IPv6 进行通信,否则也可以使用 IPv4 进行通信。Kubernetes 在 1.20 后开始支持双栈。当然,除了对 Kubernetes 版本有要求外,CNI 插件也必须支持双栈才行。
要在 Kubernetes 中开启双栈,需要做以下配置:
- kube-apiserver:
--service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR>
- kube-controller-manager:
--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR>--service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR>--node-cidr-mask-size-ipv4|--node-cidr-mask-size-ipv6对于 IPv4 默认为 /24,对于 IPv6 默认为 /64
- kube-proxy:
--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR>
IPv6 地址速查
平常接触 IPv4 地址较多,因此一眼就大概知道某个地址代表什么含义,但是 IPv6 中往往比较难分辨,这里提供一个表格供对照参考。
| 地址类型 | IPv4 | IPv6 |
|---|---|---|
| 环回地址 | 127.0.0.1 | ::1/128 |
| 私网地址 | 10.0.0.0 – 10.255.255.255, 172.16.0.0 – 172.31.255.255,192.168.0.0 – 192.168.255.255 | 前缀FC00::/7(1111 110),范围:FC~FD。 |
| 链路本地地址 | 169.254.0.0/16 | fe80::/10 |
| 组播地址 | 无 | 被请求节点组播地址由前缀FF02::1:FF00:0/104和单播地址的最后24位组成。 |
| 广播地址 | 广播地址使用该网络范围内的最大地址。 即主机部分的各比特位全部为 1 的地址。在网络 10.1.1.0/24 中,其广播地址是 10.1.1.255。 | 无 |
参考
- 华为 《IPv6 技术白皮书》。本文大多数内容都是参考或摘抄自该白皮书。
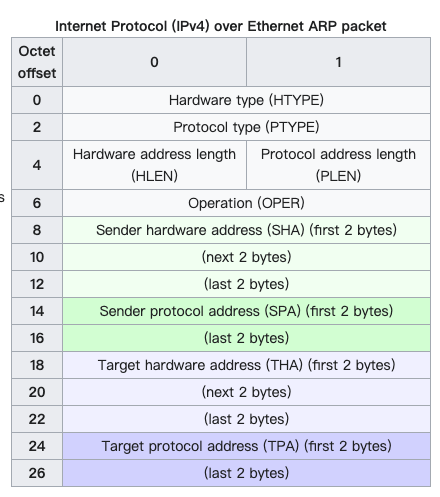

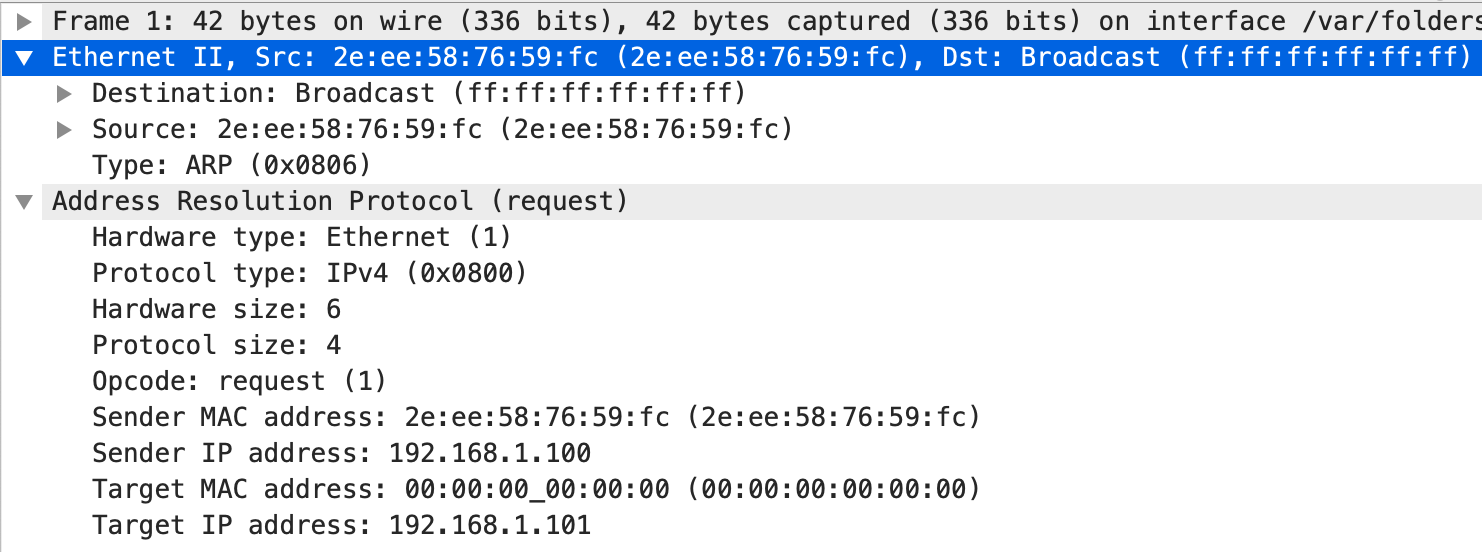
 。
。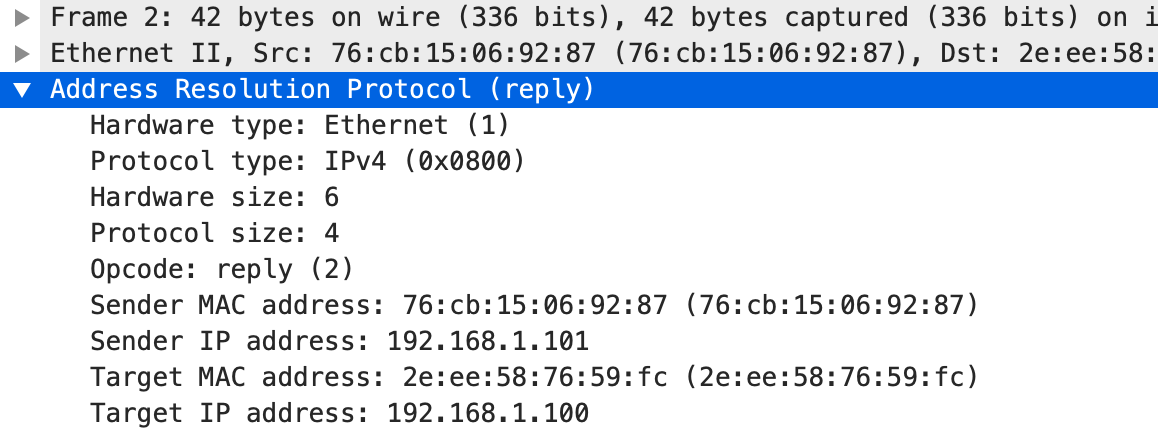 。通过这个响应我们也能知道 c1 的 MAC 地址是 2e:ee:58:76:59:fc,c2 的 MAC 地址是 76:cb:15:06:92:87。这个时候,我们也可以看一下 arp 表的情况。
。通过这个响应我们也能知道 c1 的 MAC 地址是 2e:ee:58:76:59:fc,c2 的 MAC 地址是 76:cb:15:06:92:87。这个时候,我们也可以看一下 arp 表的情况。