Contents
1.redis的使用场景
项目中存在多种redis的使用场景
1.1 场景一:缓存(key,value)
缓存是一个非常常见的场景,在项目中,可以将mysql中的一部分数据查询的结果缓存到redis中,以此来获取更快的查询速度。
以用户信息缓存为例,我的做法如下:
- 1.设定用户信息缓存的规则,比如userinfo128代表用户id为128的用户信息缓存。
- 2.在query语句执行时,先检查userinfo128是否存在,如果存在,直接取出结果返回,否则执行sql语句进行查询,并将查询结果缓存。
- 3.在update和delete语句执行时,删除userinfo128的缓存,这样下一次query时就会自动更新缓存了。
1.2 timeline(sorted set)
timeline非常经典的场景就是微博,朋友圈这种,每个用户都能在自己的timeline上获取到按时间排序的其他用户发布的动态。这里有以前总结过的一篇文章:朋友圈式的TIMELINE设计方案。
其实这个 timeline 我一开始的实现是用 list 去做的,但是用list会存在一个问题:因为推送动态可能同时发生,导致不是严格的按照时间排序。
1.3 推送用户集合(set)
这个功能其实就相当于维持一个用户的粉丝列表。这个列表是一个会经常发生变化的集合,并且在项目中是根据用户的关系链计算出来的,单次的查询会消耗很多的时间,因此做成一个集合,在需要推送动态之类的内容时,直接从redis的集合中查询,会节约很多的时间。
1.4 任务队列(list)
整个项目中很多的操作都是异步的,比如发短信,发邮件,推送用户动态等等,使用redis作为任务队列是很简单的,使用它的list结构,然后使用lpush/rpop对,一边push进任务,另一边有一个单独的后台进程pop出任务进行执行。
当然lpush/rpop并不是很好的一个选择,更好的选择是lpush/brpop,使用阻塞版本的pop指令,可以减少很多不必要的轮询。
在使用这样的任务队列时,还需要考虑到一个问题,如果在取出一个任务时进程崩溃,那么这个任务就彻底的丢失了。因此还可以使用 rpoplpush 或者阻塞版本的 brpoplpush ,取出一个任务的同时备份到另一个队列。如果执行成功的话就再lrem掉这个备份即可。关于队列的更详细的使用在第7大点有更详细的说明。
当然, Redis其实并不推荐作为任务队列的实现,如果需要的话,可以尝试使用Redis作者的另一个项目:disque,或者是kafka。
1.5 计数器(hash)
计数器我认为也算是 redis 一个常用的功能了,我认为原因有以下:
- 1.很多场景下的计数功能都是一个非常高频的操作,使用 redis 会拥有极高的性能。
- 2.redis支持原子性的自增(incre)操作,不用担心CAS(check and set)的问题。
- 3.传统数据库,如mysql,如果是MyISAM,单次的更新会带来表锁,如果是InnoDB,则带来行锁,影响并发度。
计数器的使用很简单,直接对某个key做 incr 操作,或者对某个 hash 的 key 做 hincrby 操作即可。
2.php在使用redis时,多个数据库切换的困扰
项目中使用的是phpredis这个扩展,在使用pconnect保持redis长连接时,所有对redis的操作会共用同一个redis连接。这就导致:多个进程同时使用一个redis连接,并且多个进程使用的数据库不同时导致错误。比如下方的操作:
// 进程1做以下操作
redis->select(0);redis->set("key1", "val1");
// 进程2做以下操作
redis->select(1);redis-set("key2", "val2");
但是在redis的server端,所做的操作可能如下:
select(0)
select(1)
set("key2", "val2")
set("key1", "val1")
这样就导致key1的存储错误
所以我必须在所有这样的操作中,使用MULTI/EXEC对去解决这个问题。以上代码变成:
// 进程1做以下操作
redis->multi();redis->select(0);
redis->set("key1", "val1");result->exec();
// 进程2做以下操作
redis->multi();redis->select(1);
redis-set("key2", "val2");result->exec();
事实上,使用 redis 时,同时使用多个数据库并不推荐。因为在 redis 集群中是不支持 select 命令的。
3.redis多个数据库之间的切换,对性能有影响吗?
在探讨这个问题之前,摘录官网上对 select 命令的说明:
Since the currently selected database is a property of the connection, clients should track the currently selected database and re-select it on reconnection. While there is no command in order to query the selected database in the current connection, the CLIENT LIST output shows, for each client, the currently selected database.
大致意思可以翻译为:
因为当前选中的数据库是连接的一个属性,每个客户端连接都跟踪记录了当前选中的数据库,在重新连接时会重新选择数据库。虽然没有命令是为了查询当前连接选中的数据库,但是 CLIENT LIST 的输出会显示,每个客户端当前选中的是哪个数据库。
因此 select 操作只是修改了当前连接的属性。
4.redis 有 16 个数据库,目的是什么,最佳的使用方式是什么?为什么 redis 集群不支持 select?
同样的摘录一段官网的介绍
Redis different selectable databases are a form of namespacing: all the databases are anyway persisted together in the same RDB / AOF file. However different databases can have keys having the same name, and there are commands available like FLUSHDB, SWAPDB or RANDOMKEY that work on specific databases.
In practical terms, Redis databases should mainly used in order to, if needed, separate different keys belonging to the same application, and not in order to use a single Redis instance for multiple unrelated applications.
When using Redis Cluster, the SELECT command cannot be used, since Redis Cluster only supports database zero. In the case of Redis Cluster, having multiple databases would be useless, and a worthless source of complexity, because anyway commands operating atomically on a single database would not be possible with the Redis Cluster design and goals.
大意如下:
Redis 多个不同的可选择的数据库是命名空间的一个表现形式:所有的数据库都会在同一个 RDB/AOF 文件中进行持久化。当然不同的数据库可以拥有同样的名字的键,同样的也有一些类似 FLUSHDB, SWAPDB 或 RANDOMKEY 这样的命名专门在数据库上工作的。
实际上,Redis 数据库应该主要用来分离属于一个应用的不同的键,而不是为了使用一个单独的 Redis 实例服务于多个不相关的应用。
当使用 Redis 集群时,SELECT 命名就不能使用了,因为 Redis 集群仅仅支持数据库0。在 Redis 集群的案例中,拥有多个数据库是无用的,是一种毫无价值的复杂性的来源,因为 Redis 集群的设计和目标是不可能支持 SELECT 命令的。
这里解释了为什么 Redis 被设计为有多个数据库,是为了分离同一个应用中不同的键而设计的,但是不能在多个不相关的应用中使用同一个 Redis 实例。并且还要注意在 Redis 集群中无法使用 SELECT ,因此在项目中还是不用为好。
5.redis是单进程的,如何理解?
我在第一次看到这句话时,是很不理解的。对于这种应用,不可能只有一个进程在工作啊。但是在深入了解之后,明白了这里的单进程指的是:处理 Redis 命令是单进程的。
也就是说,同一时间,在并发和并行的层面上来说,都只有一个 Redis 命令被执行。这样设计的理由我的理解有以下:
- Redis是内存数据库,所有的操作耗时都视CPU的运行速度而定,IO不可能是瓶颈,并行/并发处理带来的意义不大。
- 并行/并发会增加应用的复杂度
6.redis中使用队列的问题
在1.4小节中我提到了使用Redis作为任务队列的场景。在使用时遇到了程序运行一段时间之后,无法使用brpop获取数据的问题,并且这个程序的连接依然是存活的。
于是我用 CLIENT LIST 查看当前的连接客户端。发现服务器中有大量连接,但是很多连接的 idle 特别长,明显是很久以前的连接,这些连接我可以肯定是已经断开的。经过检查之后,发现 Redis.conf 中的 tcp-keepalive 项我设置为0了,设置为0就不会检查连接是否存活,从而导致连接一直存在。以前将 tcp-keepalive 设置为60,
那这跟 brpop 无法从 Redis 中获取数据有什么关系呢?以下是个人的猜想时间。
这要从Redis的block模型说起。Redis的网络连接是epoll模型的,所以是一个异步的io,肯定不会block一个连接。那么Redis server为了实现这样的block操作,会维持一个内部的哈希表,这个哈希表保存了哪个key上阻塞了哪些客户端。如下图所示:
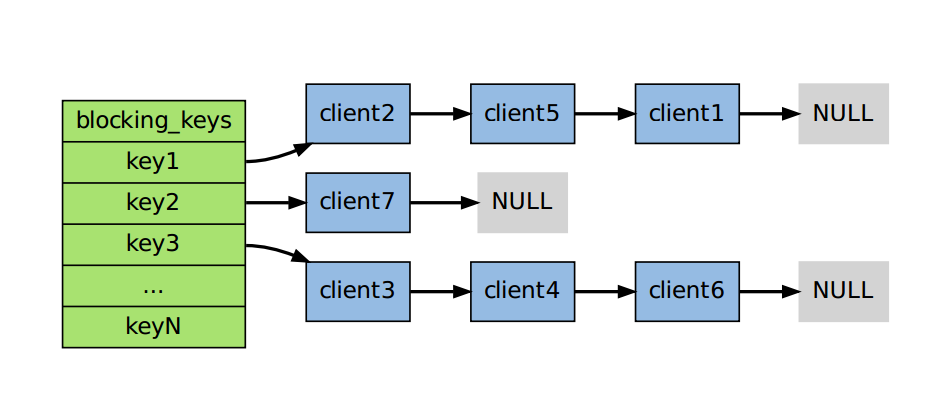
如果此时list key1中被push进了一个值,key1就被置为ready状态,然后从链表头部取出client2,将值传给它。可能在我自己的测试中,有大量的已经断开连接客户端阻塞在key1上,但是因为tcp-keepalive为0,没有被及时清除。导致以上的结果。(目前的水平只能这么解释了,虽然还有很多地方说不通)
沙发